주어진 영상에서 글자가 쓰여있는 문장영역을 검출하는 EAST라는 방법에 대해서 알아본다.
EAST란?
- " EAST : An Efficient and Accurate Scene Text Detector " ( CVPR, 2017 )
딥러닝기반 객체검출의 한가지 방법
- Multi-oriented word box detection
회전되어있는 글자들도 회전각도와 관계없이 회전된 바운딩박스로 찾아냄
- 소스코드 : GitHub - argman/EAST: A tensorflow implementation of EAST text detector
GitHub - argman/EAST: A tensorflow implementation of EAST text detector
A tensorflow implementation of EAST text detector. Contribute to argman/EAST development by creating an account on GitHub.
github.com
- 논문 : [1704.03155v2] EAST: An Efficient and Accurate Scene Text Detector (arxiv.org)
EAST: An Efficient and Accurate Scene Text Detector
Previous approaches for scene text detection have already achieved promising performances across various benchmarks. However, they usually fall short when dealing with challenging scenarios, even when equipped with deep neural network models, because the o
arxiv.org
* GPU 사용시 16fps까지 동작
EAST 입력
- Size : ( 320, 320 )
- Scale : 1 ( 0~255 )
- Mean : [ 123.68, 116.78, 103.94 ]
- RGB : false
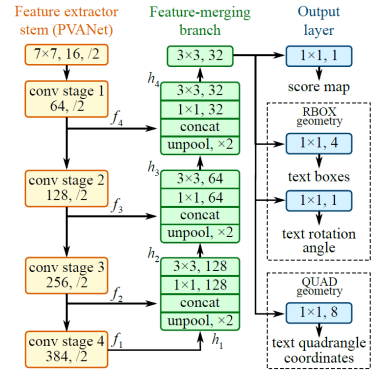
EAST 출력
- 두개의 출력 레이어
> 'feature_fusion/concat_3' 레이어
RBOX geometry map ( Rotated Box)
> 'feature_fusion/Conv_7/Sigmoid' 레이어
Score map

* EAST 알고리즘에서 출력으로 나오는 것은 위 분홍색 사각형인데 자세히보면 박스내부에 기준점이 있고
해당 점을 기준으로해서 양 4변까지의 길이값을 출력으로 주고, 전체사각형의 회전되어있는 line angle값도 출력해준다.
* 텍스트가 존재하는 부분만 위 (b) 이미지처럼 흰색으로 출력해준다. ( Score Map )
Score Map에 있는 각각의 픽셀값에 대해서 바운딩박스가 하나씩 하나씩 생기는데
예를들어 특정 Threshold값보다 큰 픽셀값이 100개가있으면 해당 100개의 픽셀에 대해서 위에서 언급한 기준점이
생기게 되고 이외는 위 설명과 같다.
그렇게 100개의 바운딩박스가 생기게되는데 모두 사용할 수는 없으니 가장 그럴듯한 바운딩박스 하나만 출력된다.
EAST 모델 & 설정 파일 다운로드
- 모델파일
https://www.dropbox.com/s/r2ingd0l3zt8hxs/frozen_east_text_detection.tar.gz?dl=1
- 설정파일
없음
- 다운로드 받은 파일을 실행폴더에 저장
코드리뷰


기존 딥러닝 방식과 동일하게 모델,설정파일을 설정해주고 네트워크를 생성해준다.
그리고 출력 레이어 실행 주석이 있는 부분은 위에서 설명했었던 두개의 출력 레이어에 대한 설명이 나오는
부분이다.
그렇게 나온 두개의 출력 레이어를 net.forwad 함수에 입력시켜주게되면 우리가 사용할 수 있게끔 변형되어
출력되게 된다.
score는 80x80 사이즈의 float 2차원 마스크 형태로 출력되는데 해당 행렬에서 값이 큰부분에 대해서만 그 위치에 텍스트가 있다고 생각하면 될 것이고,
geometry는 위에서 설명했듯이 5개의 RBOX ( 4변까지의길이, 회전된각도 )가 출력되게된다.
그러면 decode라는 함수를 사용해서 위 변수들을 풀게되면 boxes와 confidences 라는 리스트형태를 반환해주게되는데
위에서 설명햇이 수십 수백개의 박스중 가장 적합한 박스 하나만을 선택하게 해주는 것이
바로 아래에 있는 코드 NMSBoxesRotated라는 함수이다.
그래서 해당 딥러닝 방법으로 이미지에 있는 글자들의 위치를 알아낸 뒤에 Crop해서 방향을 맞추고
글자인식하는 딥러닝을 새로 추가하여 글자를 인식 및 추출할 수 있다.
* 실제로 OpenCV 예제중에서 OpenCV 3.4 Ver 중에서 Text 영역을 Detection하고 그 영역 안에서 인식까지 진행하는
딥러닝네트워크가 있는데 해당 네트워크 예제까지 제공한다.
OpenCV 4.4 Version을 찾아서 분석해보면 된다.
위에서 복잡하게 구성되어있는 함수 decode를 분석해보자면
기존에 blobFromImage에서 원본이미지를 320x320 사이즈로 리사이즈를 한 뒤 다시 score 80x80 짜리로 변형되어서 나오게되는데 해당 이미지를 스캔하다가 scoreThreshold보다 큰 값이 나오게되면 그 부분에 대해서만 바운딩박스 정보를 찾아낸다.
바운딩박스 정보를 찾아내는 방법이 복잡하지만 해당부분들을 주석에서 설명하고있기 때문에 이해할 수 있다.
'Program > 딥러닝' 카테고리의 다른 글
| Object Detection 알고리즘 정의 및 종류와 성능지표 (0) | 2025.06.10 |
|---|---|
| [Open CV] 딥러닝활용 _ 실전코딩 ( 실시간 얼굴 인식 ) (0) | 2022.08.03 |
| [Open CV] 딥러닝활용 _ OpenPose 포즈 인식 (0) | 2022.07.31 |
| [Open CV] 딥러닝활용 _ YOLOv3 객체 검출 (0) | 2022.07.26 |
| [Open CV] 딥러닝활용 _ OpenCV DNN 얼굴 검출 (0) | 2022.07.25 |