이번시간에는 YOLO v3 을 사용해서 객체 검출을 하는 방법에 대해서 알아본다.
YOLO란?
- You Only Look Once
- 실시간 객체 검출 딥러닝 알고리즘
- YOLO: Real-Time Object Detection (pjreddie.com)
YOLO: Real-Time Object Detection
YOLO: Real-Time Object Detection You only look once (YOLO) is a state-of-the-art, real-time object detection system. On a Pascal Titan X it processes images at 30 FPS and has a mAP of 57.9% on COCO test-dev. Comparison to Other Detectors YOLOv3 is extremel
pjreddie.com
YOLOv3
- 2018년 4월 발표된 Tech Report ( 논문 )
>[1804.02767] YOLOv3: An Incremental Improvement (arxiv.org)
YOLOv3: An Incremental Improvement
We present some updates to YOLO! We made a bunch of little design changes to make it better. We also trained this new network that's pretty swell. It's a little bigger than last time but more accurate. It's still fast though, don't worry. At 320x320 YOLOv3
arxiv.org
- 기존 객체 검출 방법과 성능은 비슷하고 속도는 훨씬 빠름
- COCO 데이터셋 사용
> COCO - Common Objects in Context (cocodataset.org)
> 80개 클래스 객체 검출
> 아래 홈페이지에 들어가면 수만장의 이미지들이 있어 해당 이미지로 학습을 시킬 수 있다.
COCO - Common Objects in Context
cocodataset.org

실제 YOLO 사이트에 들어가보면 YOLOv3에 대한 정확도 ( 세로축 )와 소요시간 ( 가로축 )을 볼 수 있다.

그리고 실제 사용해야 할 모델파일들과 Config 파일들이 있기 때문에 해당 홈페이지에서 다운받아야한다.
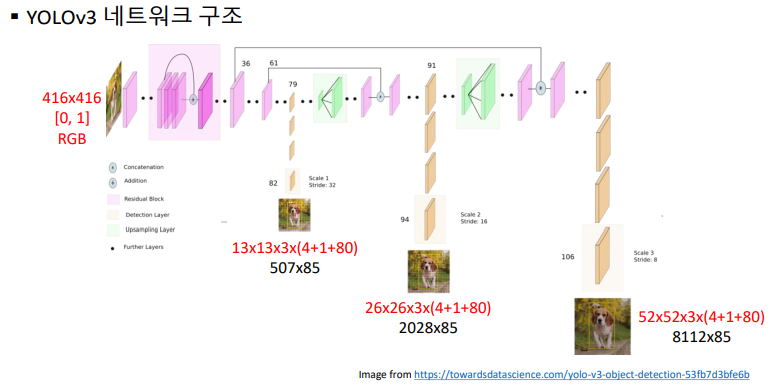
다시 말하지만 OpenCV에서 해당 방법을 가져다 쓰기 위해서는
해당 방법의 네트워크에 어떤 입력과 출력이 있는지를 알아야한다.
해서 알아보면 위 이미지에서 알 수 있듯이 입력영상으로 416 x 416 의 이미지를 주면되고
[0,1] 정규화와, RGB의 입력을 갖는다.
그리고 13x13 , 26x26, 52x52 등의 출력되는 이미지를 모두 가져와서 조합해야한다.
위 YOLO 홈페이지에 나와있는 YOLOv3 - 320, 416, 608 의 weights , cfg 파일을 보면 모두 같은
다운로드 url 인 것을 알 수 있는데 그렇다는 것은 같은 파일에 입력크기를 조절해서 사용한다는 것이다.
물론 입력영상의 크기에 따라서 속도차이가 날 수 있다. ( 320 > 416 >> 608 ) 물론 정확도는 반대이다.
YOLOv3 입력
- Size : ( 320, 320 ) , ( 416, 416 ), ( 608, 608 )
- Scale : 0.00392 ( 1/255 )
- Mean : [ 0, 0, 0 ]
- RGB : true
YOLOv3 출력
- 3개의 출력 레이어
> outs[0].shape = (507, 85), 507 = 13*13*3
> outs[0].shape = (2028, 85), 2028 = 26*26*3
> outs[0].shape = (8112, 85), 8112 = 52*52*3
실제로 사용해보기위해서 YOLO 사이트에서 Config와 Weights 파일을 다운로드 받는다.
weights 파일은 바로 다운받아지는데 Config 파일은 Github 사이트에 있는 Raw 파일을 다운받아야한다.
YOLOv3 모델 & 설정 파일 다운로드
- 모델 파일 : https://pjreddie.com/media/files/yolov3.weights
- 설정 파일 : https://github.com/pjreddie/darknet/blob/master/cfg/yolov3.cfg
GitHub - pjreddie/darknet: Convolutional Neural Networks
Convolutional Neural Networks. Contribute to pjreddie/darknet development by creating an account on GitHub.
github.com
- 클래스 이름 파일 : darknet/coco.names at master · pjreddie/darknet · GitHub
GitHub - pjreddie/darknet: Convolutional Neural Networks
Convolutional Neural Networks. Contribute to pjreddie/darknet development by creating an account on GitHub.
github.com
* 위 파일들도 마찬가지로 확장자명이 .txt가 아니다.
코드리뷰
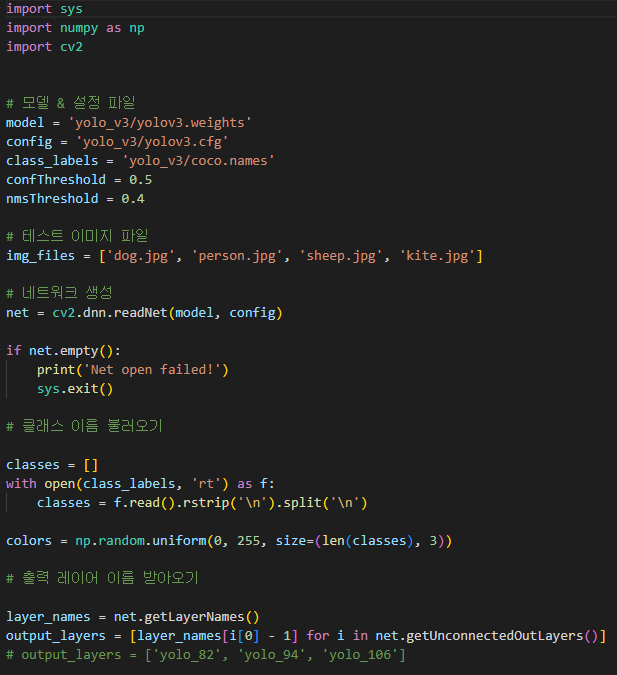

해당 코드는 다른 딥러닝 코드보다 복잡할 수 있는데
그 이유는 결과를 곧바로 나타낼 수 있으면 좋은데 결과가 3개의 ndarray로 나오기때문에 변형을 많이 해줘야하기때문
일단 위에서부터의 코드를 살펴보게되면
model, config, class_labels 이렇게 3개의 미리 다운받아놓은 파일을 확장자명과 함께 선언해주고
confThreshold , nmsThreshold 는 추후 설명하도록 한다.
그리고 테스트 이미지파일 4개를 불러와서 사용한다.
네트워크 생성은 다른 딥러닝방식과 같게 사용한다.
Opencv 에서 dnn 모듈을 호출하여 readNet 함수를 호출한다.
클래스 이름 불러오기는 Class 파일이 txt 파일이기때문에 각 라인별로 String으로 뽑아온 뒤
리스트로 만들어준다.
출력 레이어 받아오기에서는 YOLOv3 네트워크 구조를 보면 3군데에서 출력을 받아온다고 되어있는데
자세히보면 82, 94, 106번째 레이어값을 받아온다.
detection은 총 85개의 Elements로 이루어져있는데 이는 4개의 바운딩박스좌표값과 1개의 스코어값
그리고 80개의 클래스에 해당하는 매칭률값이 나오게된다.
그러면 5번째 이후의 Elements에 대해서 score를 추출하여 가장 높은 값을 해당 클래스로 지정한다.
confThreshold가 의미하는 것이 지금 설명되는데 이는 클래스가 confThreshold값 보다 커야지만 해당 물체로 인식하고
바운딩 박스를 그려주게 된다. 즉, 클래스 구분 임계점인 것이다.
그리고 바운딩박스의 값에는 LT, RB가 아닌 Bounding Box 의 CenterPoint 2점과 가로크기, 세로크기가 들어가있는데
해당 박스도 Normalize 가 되어있어서 Width와 Height를 곱해주어야한다.
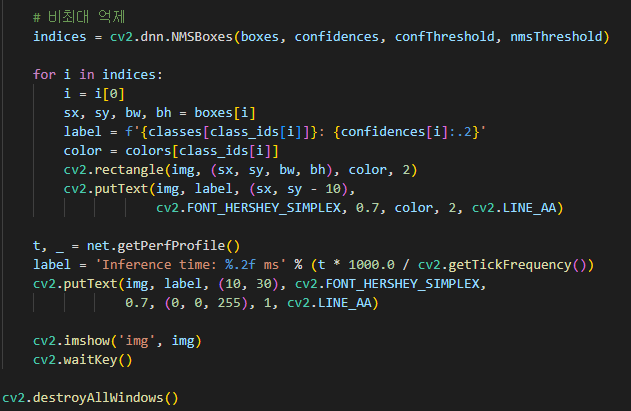
해당 바운딩 박스들을 하나의 클래스로 일단 묶어놓게되면 겹치는 박스들이 많이 생기는데
그러면 비최대 억제를 통해 하나의 박스만 골라내면 된다.
cv2.dnn.NMBoxes 함수를 통해 비최대억제를 구현할 수 있다.
( * 비최대값 억제 알고리즘 : 국지적인 최대값을 찾아 그 값만 남기고 나머지 값은 모두 삭제하는 알고리즘 )
* 속도를 빠르게하기 위해서는 리사이즈를 더 작게 해줄 수 있다.
'Program > 딥러닝' 카테고리의 다른 글
| [Open CV] 딥러닝활용 _ EAST 문자 영역 검출 (0) | 2022.08.01 |
|---|---|
| [Open CV] 딥러닝활용 _ OpenPose 포즈 인식 (0) | 2022.07.31 |
| [Open CV] 딥러닝활용 _ OpenCV DNN 얼굴 검출 (0) | 2022.07.25 |
| [Open CV] 딥러닝 _ 실전코딩 ( 한글 손글씨 인식 ) (0) | 2022.07.24 |
| [Open CV] 딥러닝 _ GoogLeNet 영상 인식 (0) | 2022.07.22 |