
이번 시간에는 사람이 손으로 쓴 글씨를 인식하기 위해서 딥러닝을 학습시키고 학습된 결과모듈을
OpenCV 모듈에 가져와서 사용하는 방법에 대해서 알아본다.
이 전에 했었던 숫자인식이나 물체 분류에 대한 것들은 서적이나 다른 예제들이 많이 나와있지만
한글 손글씨 인식에 대한 것은 많이 나와있지 않기 때문에
GitHub 에 올라와있는 한글 인식에 대한 소스코드에 대해 알아보려고 한다.
필기체 한글 인식
- TensorFlow 를 이용하여 한글 손글씨 인식을 학습하여 모델을 저장하고,
OpenCV 에서 저장된 모델을 이요하여 한글 인식을 수행하는 프로그램
- 참고사이트 : IBM " 한글 손글씨를 인식 및 번역하는 모바일앱 만들기 "
> 소스코드 : GitHub - IBM/tensorflow-hangul-recognition: Handwritten Korean Character Recognition with TensorFlow and Android
> 사용 방법에 대한 동영상 : TensorFlow Hangul Recognition - YouTube
구현할 기능
- 한글 손글씨 인식 학습
- 마우스로 한글 입력 후 인식
이 전 강의에서 했던 방식과는 크게 차이가 없지만 위 과정은 시간이 상당히 오래걸릴 수 있다.
MNIST 에서는 28 x 28 짜리의 이미지를 학습을 시키는데 10분 정도의 시간이 걸리는데
한글은 좀 더 복잡한 이미지이기때문에 64x64 짜리의 이미지를 학습 시키기 때문에 학습하는데 몇시간이 소요된다.
학습데이터를 생성하는 것도 시간이 오래 걸리고 해당 결과파일로 학습을 진행하는데도 시간이 오래걸린다.
GPU 셋팅이 되어있다면 몇십분안에 학습이 완료되겠지만 일반적인 컴퓨터라면 길게 10시간정도 소요될수도 있기때문에
해당 프로그램을 만들기 위해서는 밤에 학습 시켜놓고 아침에 다시 보는 것을 추천한다.
한글 손글씨 인식 학습 준비사항
- 소스 코드 다운로드
> GitHub - IBM/tensorflow-hangul-recognition: Handwritten Korean Character Recognition with TensorFlow and Android 에서 전체 소스 코드 다운로드 이후 , 실행 폴더 아래에 압축 해제
GitHub - IBM/tensorflow-hangul-recognition: Handwritten Korean Character Recognition with TensorFlow and Android
Handwritten Korean Character Recognition with TensorFlow and Android - GitHub - IBM/tensorflow-hangul-recognition: Handwritten Korean Character Recognition with TensorFlow and Android
github.com
- 필요한 파이썬 패키지 설치
> 설치된폴더 \ tensorflow-hangul-recognition-master 폴더에서 아래 명령 실행
pip install -r requirements.txt
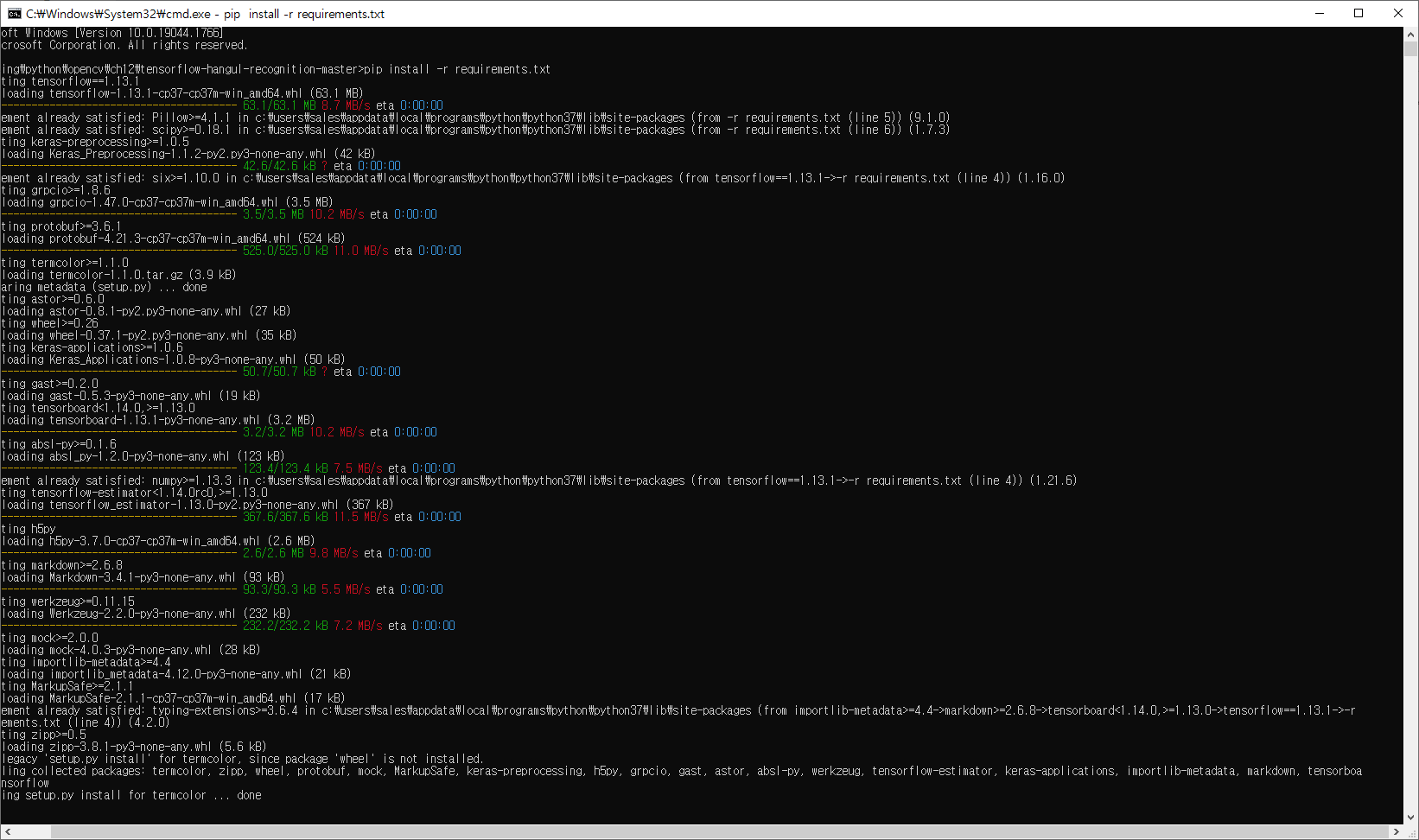
위 과정은 실제로 requirments 라는 txt 파일이 있는데 txt파일 내용을 보게되면
#numpy>=1.12.1
tensorflow==1.13.1
Pillow>=4.1.1
scipy>=0.18.1
의 내용들이 들어있는데 위 내용에 해당하는 버젼에 맞춰 패키지를 설치하는 과정이다.
- 폰트 파일 다운로드
> 강의자료에서 나와있는 software.naver.com 은 현재 중단되어있는 서비스이기 때문에
네이버 글꼴 모음 (naver.com)에서 다운로드를 진행해도 될 것 같다.
저는 클로바 나눔 손글씨 전체를 내려받았습니다.
필기체 인식이기 때문에 손글씨체를 사용해서 학습시키는 것이 더 효율적일 수도 있을 것 같습니다.
> 테스트를 위해 대략 40개의 폰트 파일 ( *.ttf ) 다운로드 후 ,
설치된폴더 \ tensorflow-hangul-recognition-master \ fonts \ 폴더에 저장한다.
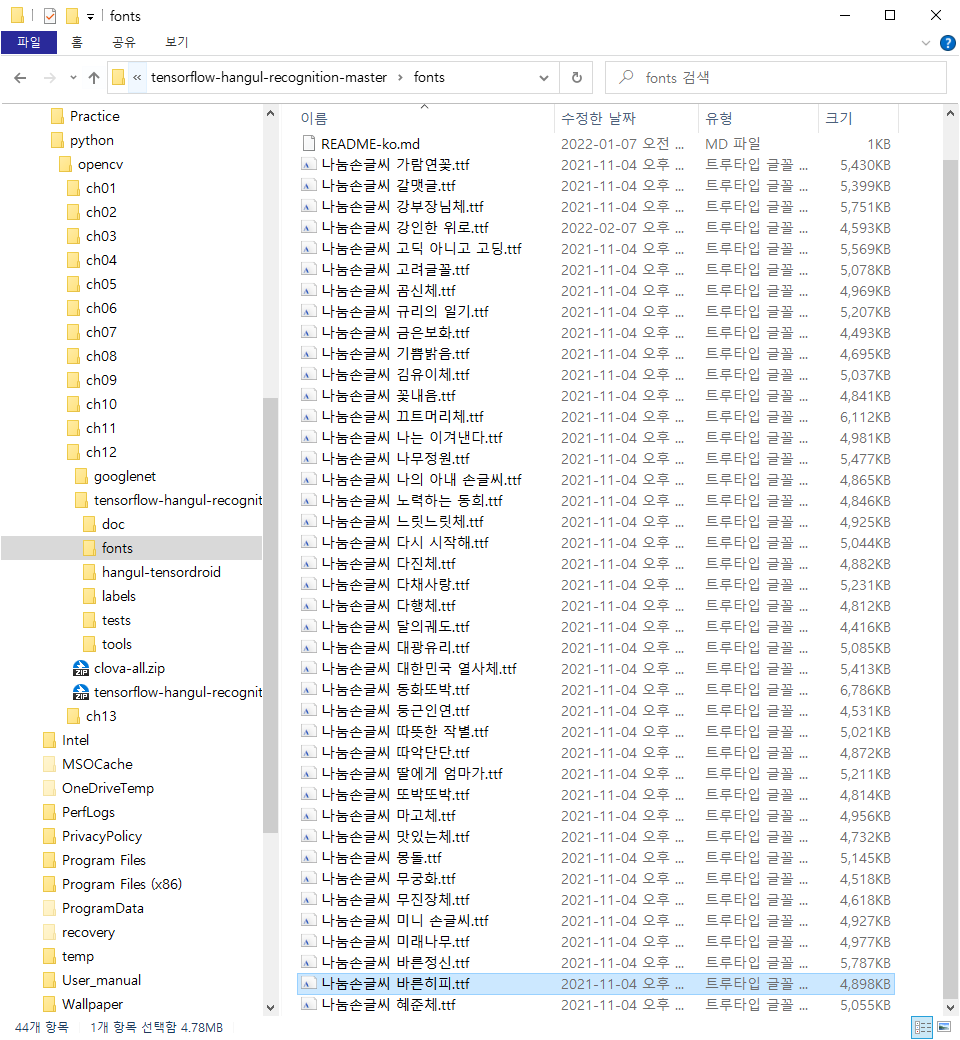
해당 폰트파일을 Python에서 불러와서 글씨를 쓸건데 64 x 64 짜리 이미지에다가 가,나,다,라 ... 써서 그걸
하나하나 이미지파일로 저장해준다.
그 Python 파일은 설치된폴더 \ tensorflow-hangul-recognition-master \ tools \ hangul-image-generator.py 에 위치해있다.
그러면 label 폴더에 아래와같은 txt 파일이있는데 한글을 조합해서 만들 수 있는 리스트를 적어놓은 txt파일이 있는데
hangul-image-generator.py에서 해당 작업을 반복해준다.

여기서 2350개의 조합을 하면 정확도나 많은 글씨인식들이 가능해지겠지만
GPU 를 사용하지않고 CPU로만 학습을 진행시키게되면 소요시간이 엄청나기 때문에 ( 하루이상 )
이 강의에서는 256개의 조합으로 학습을 진행시킨다.
- 한글 이미지 데이터 생성
python tools\hangul-image-generator.py --label-file labels\256-common-hangul.txt
> 한글 이미지 데이터 생성 후 , normalize_hangul_images.py 파일 실행 ( 위치 정규화 )
해서 위 실행 커멘드를 실행시켜보면 image-data 라는 폴더가 생기고 해당 이미지를 정규화하여 덮어쓴다.
* 나는 한글이미지 데이터 생성이 100개밖에 진행되지 않음...
- 한글 이지미를 TFRecords 로 변환
> python tools\convert-to-tfrecords.py --label-file labels\256-common-hangul.txt
- 모델 학습
실행폴더 \ 폴더에 있는 hangul_model_for_opencv.py 파일을
실행폴더 \tensorflow-hangul-recognition-master 폴더로 복사
> python hangul_model_for_opencv.py --label-file labels\256-common-hangul.txt
이렇게 학습이 되고나면
* 제 노트북에서는 어떤 에러인지는 모르겠는데 현재 진행이 되지 않아 결과만 보겠습니다.

위와같이 Korean_recognition . pb 파일이 생성이 되어있다.
그러면 위 파일이 64 x 64 짜리의 영상에 대해서 한글을 인식할 수 있는 학습된 결과이다.
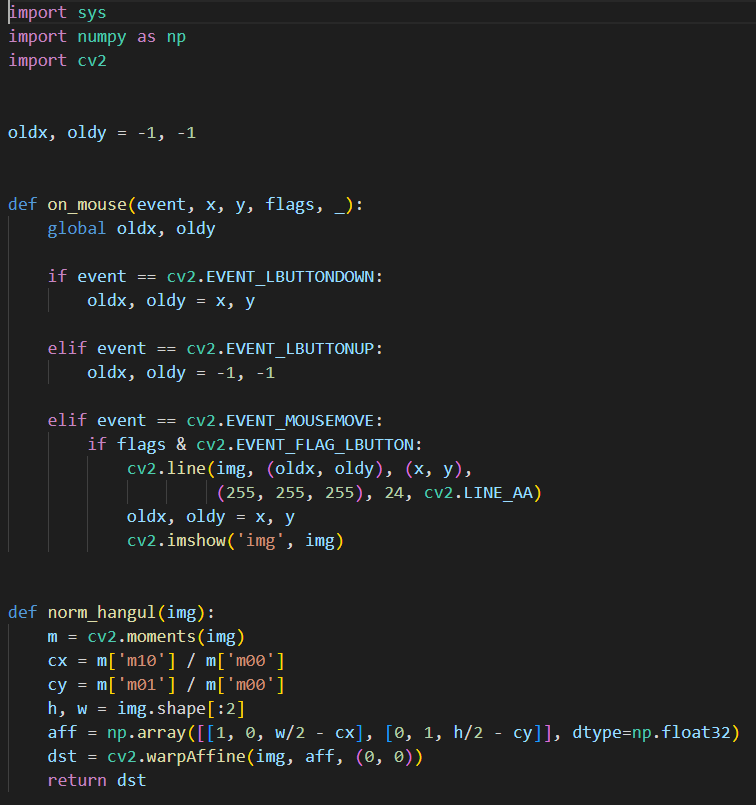
코드리뷰

'Program > 딥러닝' 카테고리의 다른 글
| [Open CV] 딥러닝활용 _ YOLOv3 객체 검출 (0) | 2022.07.26 |
|---|---|
| [Open CV] 딥러닝활용 _ OpenCV DNN 얼굴 검출 (0) | 2022.07.25 |
| [Open CV] 딥러닝 _ GoogLeNet 영상 인식 (0) | 2022.07.22 |
| [Open CV] 딥러닝 _ MNIST 학습 모델 사용하기 (0) | 2022.07.21 |
| [Open CV] 딥러닝 _ OpenCV DNN 모듈 (0) | 2022.07.19 |