구글넷이라는 영상 인식을 가져와서 OpenCV에서 실행하는 방법에 대해서 알아본다.
구글넷에 대해서는 아래 링크에서 설명한 적이 있다.
https://opencv-master.tistory.com/119?category=1110856
[Open CV] 딥러닝 _ CNN 이해하기
딥러닝에서 영상을 다룰 때 필수적으로 사용되고 있는 CNN이라는 구조에 대해서 알아본다. 컨볼류션 신경망 ( CNN : Convolutional Neural Network ) - 영상 인식 등을 위해 필수적으로 사용되고 있는 딥러
opencv-master.tistory.com
GooLenet 방법은 1000개의 카테고리를 분류할 수 있다고 나오는데
예를들어 개와 고양이를 구분한다고 하면 단순히 개 또는 고양이로 분류하는 것이 아니라
고양이면 어떤 고양이인지 페르시안 고양이인지 이집트 고양이인지등 또는 개면 진돗개인지 리트리버인지 등에 대한
분류까지 모두 할 수 있는 알고리즘이다.
그래서 2014년에는 판단할 수 있는 능력이 사람의 품종 구분능력 오차가 5%정도인데
해당 알고리즘은 약 6%의 오차범위가 발생했다고 한다.
즉, 사람과의 인식 능력이 1%의 차이를 보인 것 이다.
중요한 것은 알고리즘을 사용할 때 네트워크의 입력을 어떻게 줘야하는지, 그리고 네트워크에 어떤 입력영상을 줬을 때
그 결과가 어떻게 나오는지 그결과를 내가 어떻게 분석해야되는지에 대한 정보를 알아야 한다는 것이다.
- 입력 : 224 x 224 , BGR 컬러 영상, 평균 값 = ( 104, 117, 123 )
- 출력 : 1x1000 행렬, 1000개 클래스에 대한 확률 값
입력에 대한 정보를 보면 224 x 224 사이즈로 학습이 되었기 때문에 실제 사용할때도 입력영상을 224 x 224 사이즈로
resize 를 해서 사용해야한다. 그리고 BGR 컬러영상이기때문에 Convert 해줄 필요가 없다.
그리고 Mean 값을 104 117 123을 사용했기 때문에 해당 값을 그대로 사용해주면 된다.
출력은 1x1000 행렬인데 ( 1000개 클래스에 대한 확률 값 ), 1000개의 원소중에서 가장 큰 값을 추출하여
해당 추출 값을 결과값으로 사용한다.
미리 학습된 GoogLeNet 학습 모델 및 구성 파일 다운로드
• Caffe Model Zoo: https://github.com/BVLC/caffe
▪ 모델 파일: http://dl.caffe.berkeleyvision.org/bvlc_googlenet.caffemodel
▪ 설정 파일: https://github.com/BVLC/caffe/blob/master/models/bvlc_googlenet/deploy.prototxt
• ONNX model zoo: https://github.com/onnx/models
▪ 모델 파일: https://github.com/onnx/models/tree/master/vision/classification/inception_and_googlenet/googlenet
• 클래스 이름 파일:
▪ 1~1000번 클래스에 대한 설명을 저장한 텍스트 파일
▪ https://github.com/opencv/opencv/blob/4.1.0/samples/data/dnn/classification_classes_ILSVRC2012.txt
위 zoo라고 하는 것은 Caffe , ONNX, TensorFlow 등에서 미리 학습된 FrameWork들을 모아놓은
자료실이라고 보면된다.
예를들어 Caffe zoo 를 보면 Caffe를 이용해서 학습을 시켜놓은 모델파일을 다운로드 받을 수 있는 깃허브 사이트로 연결된다.
해서 현재 사용해야 할 내용의 모델파일을 위 링크를 통해 들어가서 다운로드 받고 설정파일을 다운로드 받는데
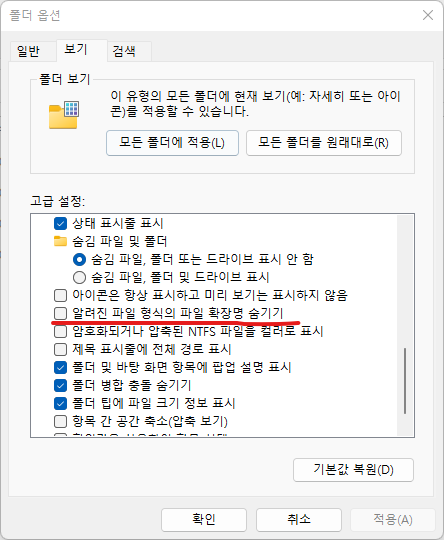
설정파일을 다운로드 받을때 FireFox가 아닌 크롬등의 다른 프로그램을 사용해서 Raw 파일을 저장하게되면
protxt의 확장자가 아닌 protxt.txt의 확장자가 한번 더 붙어서 나오게 된다.
따라서 확장자를 protxt로 다시 변환시켜줘야 한다.
확장자가 변경되지 않을 경우에는 아래처럼 확장자 명을 표시하여 바꿔준다.

이렇게까지 설정이 완료된다면 Caffe 에서 학습된 GoogLeNet 을 사용할 수 있는 것이다.
그리고 한가지만 더 해보자면 ONNX 에 관해서 알아본다.
위 ONNX 모델에 들어가보면 Vision 이라는 폴더가 보이는데 해당 폴더가
우리가 사용하는 Vision 관련된 모델들이 들어있는 곳이다.
그러면 우리가 사용해야 할 GoogLeNet이 들어있는 곳은 classification에 Inception_and_googlenet에있는 파일을
다운받으면 Binary 파일이 다운로드되는데 이를 사용하면 된다.
그리고 마지막으로 클래스 이름 파일을 다운로드 받아야한다.
우리가 0부터 999개까지의 클래스를 분류하는데 해당 클래스에 대한 설명을 저장한 텍스트 파일이다.
그래서 위 클래스 이름파일에 들어가게되면
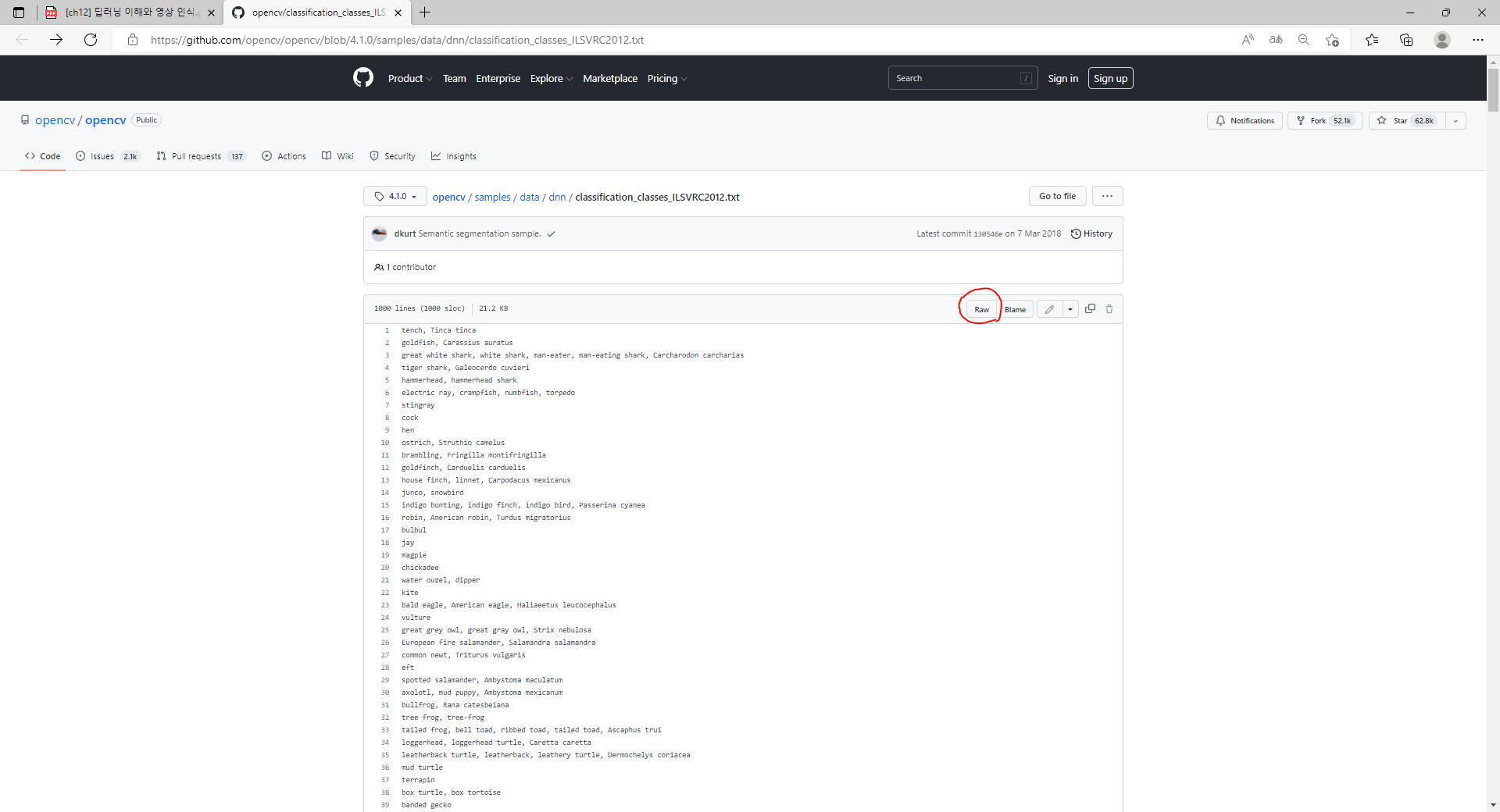
위와같이 Raw 파일을 다운받을 수 있는 사이트가 뜬다.
그러면 Raw 버튼을 클릭하여 이 전과 같은 방법으로 적용시켜준다.
코드리뷰
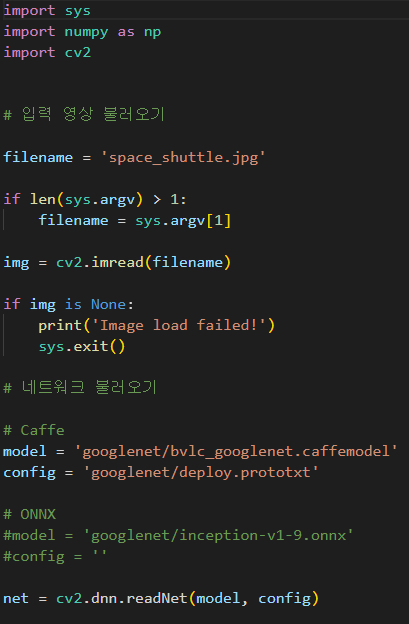
처음에 space_shttle이라는 jpg파일을 로드한다.
space_shuttle 이미지는 아래의 이미지와 같다.

그리고 해당 이미지를 분류하기 위한 코딩을 시작한다.
* if len ( sys.argv ) > 1: filename = sys.argv[1]이 의미하는 것은 command창을 이용해서 python을
실행할때 파일이름을 옆에 작성하여 불러오면 바로 GoogLeNet을 실행할 수 있도록 하게 함이다.

그리고 네트워크를 불러오는데 Caffe 를 불러올지 ONNX를 불러올지를 결정한다.
결정했다면 어떤 model과 config를 사용할지 결정해서 경로를 작성해준다.
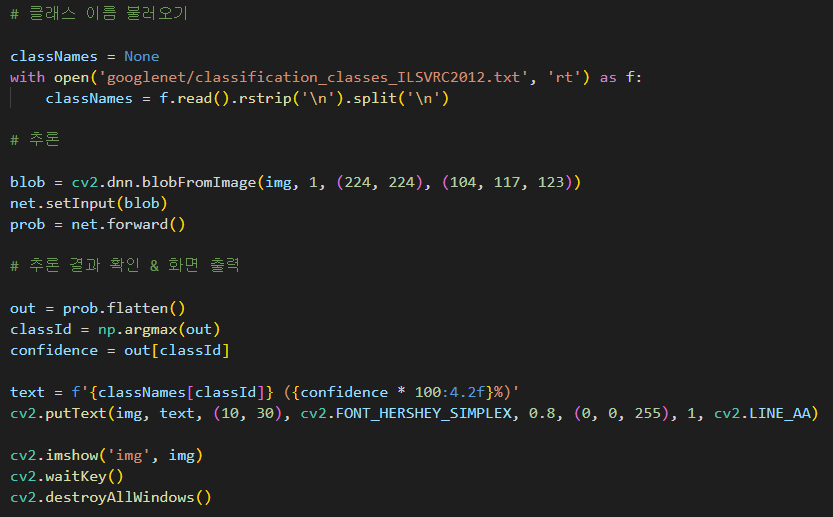
이후 코드는 이 전에 배운 딥러닝 관련 코드와 유사한데 우리는 지정되어있는 클래스 이름을 가져와야한다.
따라서 with open 함수를 이용하여 아까 다운받았던 클래스 이름 txt파일을 로드해준다.
그럼 classNames 라는 리스트에 입력이 된다.
그리고 아까 Mean 값을 104, 117, 123으로 한다고 했는데
이는 Caffe 의 설정파일 ( deploy.prototxt ) 을 다운 받는 사이트 경로의 한개의 상단폴더에 보면
train_val.prototxt 라는 파일이 있는데 해당 파일을 보게되면 mean값을 찾아볼 수 있다.

이후 코드는 이전에 나왔던 코드와 같다.
'Program > 딥러닝' 카테고리의 다른 글
| [Open CV] 딥러닝활용 _ OpenCV DNN 얼굴 검출 (0) | 2022.07.25 |
|---|---|
| [Open CV] 딥러닝 _ 실전코딩 ( 한글 손글씨 인식 ) (0) | 2022.07.24 |
| [Open CV] 딥러닝 _ MNIST 학습 모델 사용하기 (0) | 2022.07.21 |
| [Open CV] 딥러닝 _ OpenCV DNN 모듈 (0) | 2022.07.19 |
| [Open CV] 딥러닝 _ 딥러닝 학습과 모델 파일 저장 (0) | 2022.07.18 |