비지도 학습 k-평균 알고리즘에 대해 알아본다.
k - 평균 ( k-meas ) 알고리즘
- 주어진 데이터를 k 개의 구역으로 나누는 군집화 알고리즘

- 지도학습처럼 해답을 주는 것이 아니고 데이터를 입력을 주고 임의의 기준으로 나눠주는 형태로
동작시키는 알고리즘 ( 머신러닝 이해하기글 참고 )
https://opencv-master.tistory.com/72?category=1092621
머신러닝 이해하기 (1)
본 포스팅은 패스트캠퍼스 OpenCV를 활용한 컴퓨터비전과 딥러닝 올인원 패키지를 참고하여 작성하였습니다. 머신러닝 ( Machine Learning ) 이란? - 주어진 데이터를 분석하여 규칙성, 패턴 등을 찾고,
opencv-master.tistory.com

- 이 전 k-mean shift 알고리즘과 비슷하게 특정 데이터의 중심점 좌표가 이동하지 않을때까지 반복 계산하는
방법과 비슷하게 동작한다.
- 각각의 군집들의 평균을 계산하면서 해당 평균값이 움직이지 않을때까지 반복적으로 계산한다.
- 처음 중심점을 어떻게 잡는지에 따라서 결과가 다르게 나올수도 있기때문에 중심점을 잘 잡는 것도 중요하다.
- 동작순서
1. 임의의 k개 중심을 선정
2. 모든 데이터에 대하여 가장 가까운 중심을 선택
3. 각 군집에 대해 중심을 다시 계산
4. 중심이 변경되면 2~3 과정을 반복
5. 그렇지 않으면 종료
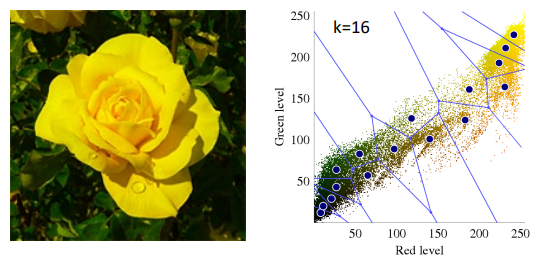
k-평균 알고리즘을 이용한 컬러 영상 분할
- 입력 영상의 각 필셀 값을 색 공간 상의 한 점으로 표현
( e.g.) RGB 3차원 공간에서의 한 점, HS 2차원 공간에서의 한 점
- 색 공간에서 K-평균 알고리즘 수행
- 각 픽셀 값을 k개의 대표 색상으로 치환
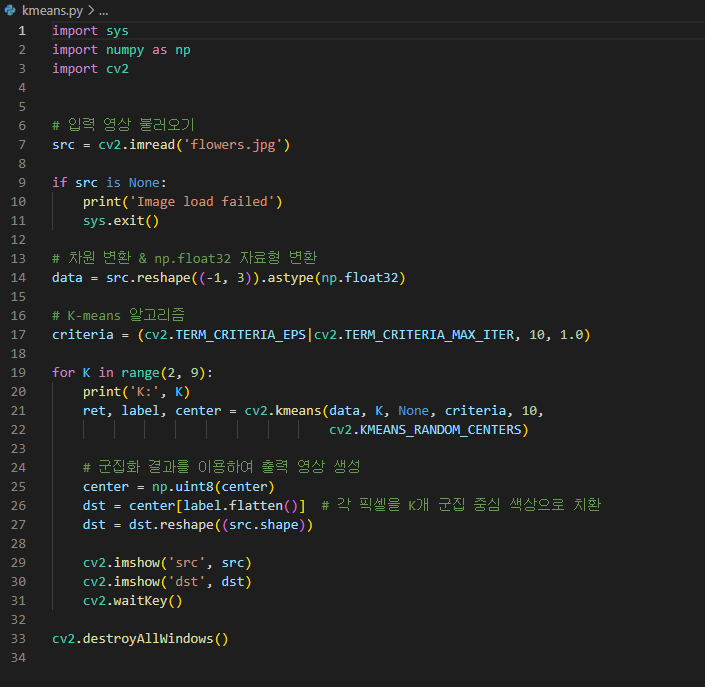
k - mean 군집화 함수
cv2.kmeans ( data, k, bestLabels, criteria, attempts, flags, centers = None )
-> retval, bestLabels, centers
data : 학습 데이터 행렬
k : 군집 개수
bestLabels : 각 샘플의 군집 번호 행렬
criteria : 종료 기준 ( type, maxCount, epsilon ) 튜플
attempts : 다른 초기 레이블을 이용해 반복 실행할 횟수
flags : 초기 중앙 설정 방법. cv2.KMEAS_RANDOM_CENTERS, cv2.KMEANS_PP_CENTERS, cv2.KMEANS_USE_INITIAL_LABELS 중 하나
centers : 군집 중심을 나타내는 행렬
retval : Compactness measure
위 값이 작게나올수록 평균점이 군집중심에 가까이 붙어있다라고 볼 수 있다.

'Program > 머신러닝' 카테고리의 다른 글
| [Open CV] 머신러닝 _ 실전코딩 _ 문서 필기체 숫자 인식 (0) | 2022.07.15 |
|---|---|
| [Open CV] 머신러닝 _ 숫자 영상 정규화 (0) | 2022.07.12 |
| [Open CV] 머신러닝 _ HOG+SVM 필기체 숫자 인식 (0) | 2022.07.11 |
| [Open CV] 머신러닝 _ OpenCV SVM 사용하기 (0) | 2022.07.10 |
| [Open CV] 머신러닝 SVM 알고리즘 (0) | 2022.07.09 |