
이번에는 OpenCV에서 SVM 알고리즘을 사용하는 방법에 대해서 알아본다.
SVM 알고리즘을 사용하기 위해서는 SVM 객체를 먼저 생성해줘야한다.
SVM 객체 생성
cv2.ml.SVM_create() -> retval
- retval : cv2.ml_SVM 객체
SVM 타입 지정
cv2.ml_SVM.setType ( type ) -> None
- type : SVM 종류 지정. cv2.ml.SVM_으로 시작하는 상수.

SVM 커널 지정
cv2.ml_SVM.setKernel ( kernelType ) -> None
- kernelType : 커널 함수 종류 지정. cv2.ml.SVM_으로 시작하는 상수

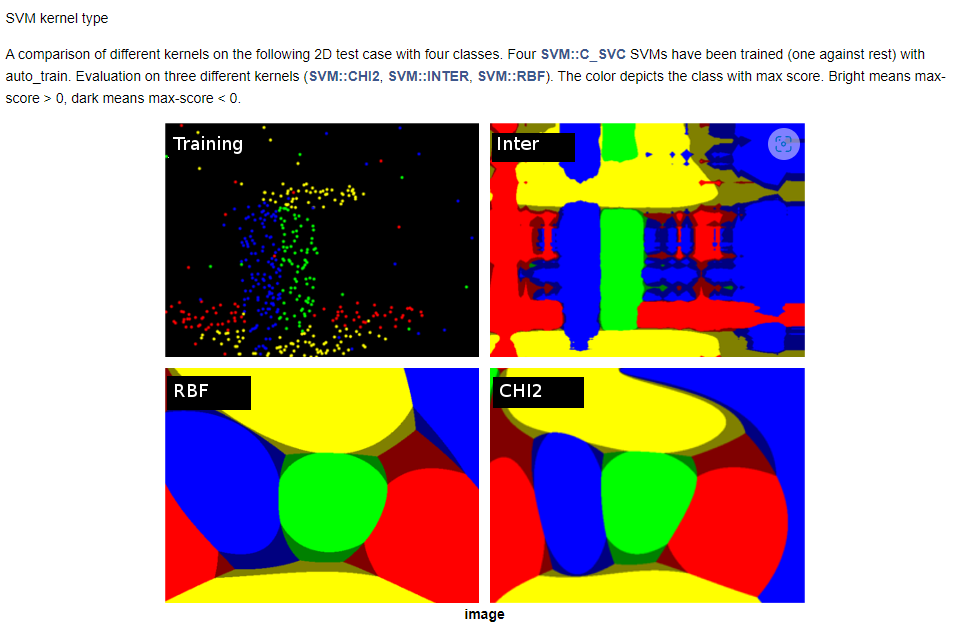
커널 타입에 관한 이미지를 OpenCV Documents에 들어가서 살펴보면
위와같은 이미지를 얻을 수 있는 것이 커널 타입이라고 설명되어있다.
보통 타입으로 C-SVC 와 Linear가 아닌 형태로는 RBF 타입을 많이 선호한다.
그러면 위에서 나온 C라는 값과 Gamma라는 값 ( 파라메타 ) 들을 잘 입력해줘야만
SVM 알고리즘이 데이터들을 잘 구분해준다.
그렇다는 말은 위 파라메타값들을 잘못주면 구분이 어렵다는 말과 같다.
그러면 위 인자들을 어떻게 줘야할지 데이터가 워낙 방대해서 잘 구분할 수 없기때문에
OpenCV에서는 trainAuto 라는 자동학습 함수를 제공해준다.
SVM 자동 학습 ( k-폴드 교차 검증 )
cv2.ml_SVM.trainAuto ( samples , layout, responses, kFold = None, ... ) -> retval
- samples : 학습 데이터 행렬. numpy.ndarray.shape = ( N,d ), dtype = numpy.float32.
- layout : 학습 데이터 배치 방법. cv2.ROW_SAMPLE 또는 cv2.COL_SAMPLE.
- responses : 각 합습 데이터에 대응되는 응답 ( 레이블 ) 벡터. numpy.ndarray.
shape = (N, ) 또는 ( N,1). dtype = numpy.int32 또는 numpy.float32.
- kFold : 교차 검증을 위한 부분 집합 개수
- retval : 학습이 정상적으로 완료되면 True.
* 위 samples layout responses 라는 인자들은 이 전 Statemodel이라는 함수에서 사용됐었던 인자이기 때문에
참고해서 사용하면 된다.
* 위에 나와있는 ... 의 인자는 C, Gamma, Degree 등등의 인자들의 범위를 설정해주는 파라메타들인데
보통 Default 로 설정되어 있는 기본범위 내부에서 설정이 된다.
따라서 보통의 경우에 위 3가지의 인자만 지정해주면 된다.
* 따라서 위 함수를 사용하게되면 C값과 Gamma 값 Degree값 등등이 자동으로 설정되게 되기때문에 편하게
사용할 수 있는데 위 범위 값 내부에 있는 경우를 모두 Training 해보기 때문에 기본적으로 실행속도가 느리다는
단점이 있다.
* 그래서 권장되는 방법은 가지고있는 데이터에서 몇개만 랜덤하게 추출해서 그걸 사용해서 TrainAuto로 학습을 시켜보고
나온 C값과 Gamma 값을 이용해서 Train 함수를 사용하여 학습시키는 것을 권장한다.
실제 코딩 결과

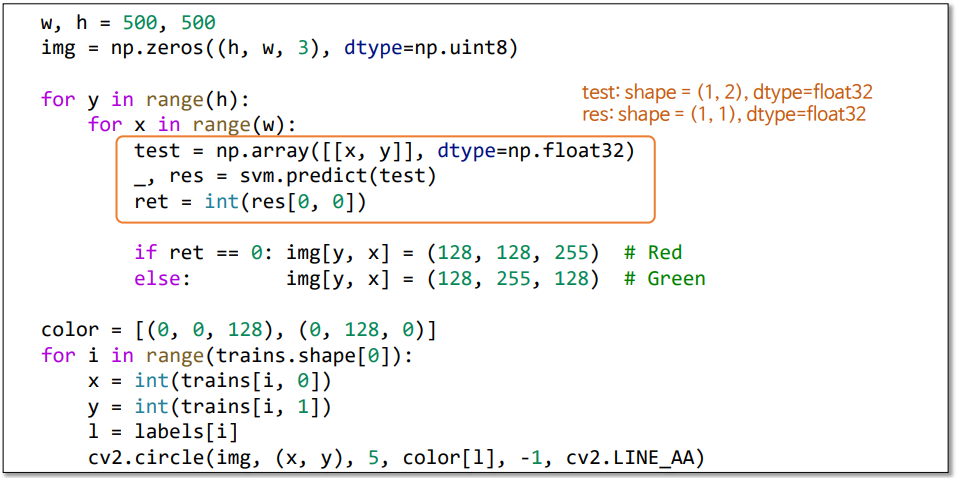
위 코드를 보게되면 8개의 좌표로 이루어진 array 가 있는데 이를
앞4개는 0번클래스 뒤 4개는 1번클래스로 지정해준다.
이후 TainAuto 함수를 사용해서 C값과 Gamma 값을 리턴 받는다.
그리고 zeros 이미지 윈도우를 하나 생성하여 Width 와 Height 에 대한 Test 샘플을 만든다.
그리고 test를 svm.predict 함수에 입력시켜준다.
그러면 ret 변수에 res [ 0,0 ] 즉, 해당 샘플이 몇번 클래스인지를 분류해준다.
그러면 나온 결과들을 사용하여 빨간색, 초록색으로 해당 이미지의 픽셀들이 구분된다.
그리고 학습에 사용된 데이터들은 작은 원의 형태로 표시하도록 했다.

그럼 이번에는 RBF 라는 알고리즘을 사용해서 분류해본다.

따라서 지금 사용하고있는 C값과 Gamma 값을 사용하게되면 분류가 잘 되는 것을 볼 수 있는데
아까 말했었던 것 처럼 Training 하여 나온 C값과 Gamma 값을 사용하여 SetGmma, SetC 함수를 사용하면
더 빠른 속도로 동작하는 것을 볼 수 있다.

이렇게 C값과 Gamma 값을 지정하게 되면 TrainAuto가 아닌 train 함수를 사용해서 학습시킬 수 있다.
지금은 8개의점으로 학습시키고있어 속도의 체감은 없지만 실제 많은 데이터들을 기반으로 사용하게 되면
Auto와 차이가 크다고 한다.
'Program > 머신러닝' 카테고리의 다른 글
| [Open CV] 머신러닝 _ 숫자 영상 정규화 (0) | 2022.07.12 |
|---|---|
| [Open CV] 머신러닝 _ HOG+SVM 필기체 숫자 인식 (0) | 2022.07.11 |
| [Open CV] 머신러닝 SVM 알고리즘 (0) | 2022.07.09 |
| [Open CV] 머신러닝 k 최근접 이웃 알고리즘 (0) | 2022.07.08 |
| [Open CV] 머신러닝 k 최근접 이웃 알고리즘 (0) | 2022.07.07 |