
이번 시간에는 전일 배웠던 K최근접 알고리즘을 사용해서 필기체 숫자 인식하는 프로그램에 대해 알아본다.
만약 정해진 폰트로 인쇄된 숫자라면? ( 인쇄체 숫자 )
- 템플릿 매칭으로도 가능

하지만 필기체숫자는 사람마다 다르기 때문에 템플릿매칭으로는 구분하기가 쉽지 않다.
따라서 필기체 숫자의 분류를 위해서는 다수의 필기체 숫자데이터를 이용해서 머신러닝의 도움을 받아
특징점을 추출해 알아서 분류하게끔 하는 것이 일반적인 방법이다.
필기체 숫자 데이터는 OpenCV에서 제공하는 필기체숫자 파일이 있는데 이를 머신러닝으로
학습시켜 필기체 숫자를 구분한다.
https://github.com/opencv/opencv/blob/master/samples/data/digits.png
GitHub - opencv/opencv: Open Source Computer Vision Library
Open Source Computer Vision Library. Contribute to opencv/opencv development by creating an account on GitHub.
github.com

각각의 숫자는 20x20픽셀로 구성이 되어있고 가로로 100개 , 세로로 50개로 구성되어있다.
따라서 2000 x 1000의 해상도로 구분되어있다.
그러면 위 이미지의 왼쪽부터 400개는 Training으로 사용하고 나머지 100개는 Test 용도로 사용해도되지만
이번 시간에는 전체 데이터를 ( 500개 ) Training 시키고 직접 쓴 필기체를 구분하도록 프로그램할 예정이다.
KNN 필기체 숫자 인식
* 현재 필기체를 검사할 때 KNN 알고리즘을 사용하는 이유는 누구나 들었을때 이해하기가 가장 쉬운
머신러닝 알고리즘이기 때문에 사용하는 것이지 효율이 상당히 높기때문에 사용하는 것은 아니라고 한다.
- 20x20 크기 영상의 픽셀 값을 이용하여 400개의 픽셀을 일렬로 나열하게되면 1x400짜리 벡터가 만들어진다.
400차원 공간에서 한 점의 좌표를 생성
- 400차원 공간에서 KNN 알고리즘 점 분류
- 이번시간에는 픽셀값 자체를 사용하는 방법으로 설명을 하지만 이 방법이 좋은 방법은 아니다.
실제로는 이런 방식을 사용하면 안되지만 가장 간단한 형태를 구현하기 위한 방법으로 사용한다.

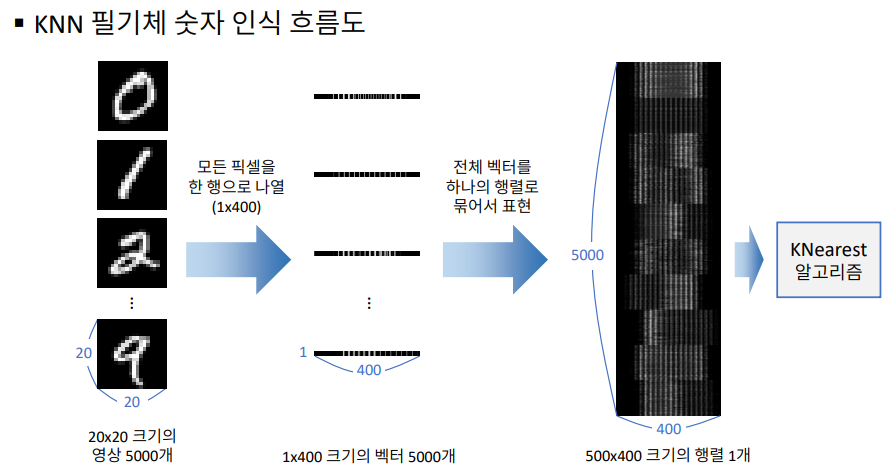
위 이미지에서 나온 것 처럼 20x20 크기의 영상을 일렬로 펼치게되면 400개의 벡터가 구성되는데
구성된 벡터들을 모두 모으게되면 500( 개의 숫자데이터 ) x 400 ( 한숫자영상의 구성벡터 ) 의 행렬이 나오게된다.


일단 digit 영상을 GrayScale로 불러와서 세로로 20씩 가로로 20씩 잘라낸다.
그럼 cells가 리스트 형태로 만들어지는데 이를 ndarray 형태로 변환시켜준다.
그리고 위에서 설명했었던대로 5000x400 행렬형태의 Training 이미지를 만들어준다.
이후 우리가 마우스로 그린 그림을 20x20 사이즈의 이미지로 리사이즈해준 뒤
400개의 공간벡터로 변환하여 해당 벡터를 위 digits 영상과 비교하여 가장 비슷한 숫자의 결과를 도출한다.
하지만 실제로 실행해보면 생각만큼 결과가 제대로 나오지는 않는다.
이유를 보면


위 2개의 이미지를 보면 알 수 있는데
5의 위치가 상단이미지는 올라가있고 하단이미지는 내려가있다.
그러면 리사이즈를 하고 특징벡터를 나열할때 하단에 있는 5는 특징벡터가 뒤로 밀리게된다.
그러니까 픽셀값을 그대로 사용하게 될 경우 이동변환에대해 예민하게 반응할 수 밖에없는 결과를 도출하는 것이다.
'Program > 머신러닝' 카테고리의 다른 글
| [Open CV] 머신러닝 _ OpenCV SVM 사용하기 (0) | 2022.07.10 |
|---|---|
| [Open CV] 머신러닝 SVM 알고리즘 (0) | 2022.07.09 |
| [Open CV] 머신러닝 k 최근접 이웃 알고리즘 (0) | 2022.07.07 |
| [Open CV] 머신러닝 클래스 (0) | 2022.07.06 |
| 머신러닝 이해하기 (2) (0) | 2022.06.01 |