2022.06.16 금일은 캐스케이드 분류기 얼굴검출에 관한 강의였다.

Viola - Jones 얼굴 검출기
- Positive 영상 ( 얼굴 영상 ) 과 negative 영상 ( 얼굴이 아닌 영상 )을 훈련하여 빠르고 정확하게 얼굴 영역을 검출
- 기존 방법과의 차별점
유사 하르 ( Haar-like ) 특징을 사용
AdaBoost 에 기반한 강한 분류 성능
( * 간단한 형태의 분류기를 여러개 모아서 강력한 형태의 분류기로 )
캐스케이드 ( cascade ) 방식을 통한 빠른 동작 속도
- 기존 얼굴 검출 방법보다 약 15배 빠르게 동작
2001년 이전까지는 주먹구구식으로 얼굴을 검출했었는데 ,
( 예를들면 살색을 검출하고 눈, 코등의 주변에서 엣지를 검출하는 등으로의 방식 )
하지만 Viola-Jones 얼굴 검출기의 논문이 나온 뒤에는 기존 주먹구구식의 방식보다는
정확하고 굉장히 빠른 속도로 검출하게 되었다.
최근까지도 많이 사용되고있기는 하지만 딥러닝 기반의 얼굴 검출시도도 많아지고 있다.
유사 하르 특징 ( Haar-like features )
- 사각형 형태의 필터 집합을 사용
- 흰색 사각형 영역 픽셀 값의 합에서 검정색 사각형 영역 픽셀 값을 뺀 결과 값을 추출
- 24 x 24 부분 영상에서 얼굴 판별에 유용한 유사 하르 특징을 선별
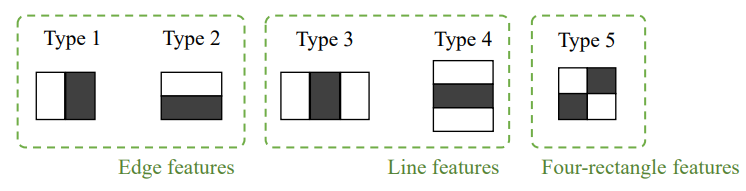
위와같은 필터 마스크를 이용해서, 검은색은 픽셀값을 모두 빼주고 하얀색은 픽셀값을 모두 더해주는
연산으로 얼굴을 판단하게 된다.
실제 얼굴을 보게되면 눈쪽은 눈썹 눈동자 엣지등이 있어서 어둡게 나오고
눈 아래 쪽은 밝게 나오게된다.
그리고 눈쪽의 사이 미간 부분에는 밝게나오고 눈쪽은 어둡게 나오게된다.
이런 특징들을 추출해 위 마스크와 연산하게된다.

눈 부분만 예를 들었지만 코나 입들도 보게되면
콧등쪽은 밝고 콧등 주변은 어둡고 입술은 어둡고 입술 위아래를 밝고 등의 특징들을 추출하여
필터마스크를 연산하게되기도 한다.
주변 특징을 모으는 것은 AdaBoost 분류를 활용해서 모으게되고 약 6000개 이상의 특징값을
추출하여 부분영상에 적용한다.
하지만 6000개 이상의 특징들을 모든 부분영상에 적용시키게되면 연산속도가 굉장히 오래걸리기 때문에
캐스케이트 분류기를 사용하게된다.
캐스케이드 분류기 ( Cascade classifier )
- 일반적인 영상에는 얼굴이 한 두개 있을 뿐, 나머지 영역은 대부분 non-face 영역
- Non-face 영역을 빠르게 skip하도록 다단계 검사 수행

캐스케이브 분류에서는 얼굴이 아닌부분이 보통 영상에서 많기때문에 얼굴이 아닌 부분을
먼저 걸러내는 것을 목표로한다.
따라서 중요한 특징들을 필두로하여 얼굴 검출을 하고 얼굴이 아니면 Fail를 반환하여
시간과 연산을 크게 단축한다.
https://www.youtube.com/watch?v=hPCTwxF0qf4
실제로 위 영상을 보게되면 캐스케이드 검출을 사용하는 것을 볼 수 있는데
박스가 오래 멈춰있는 곳은 단계가 높은 곳에서 특징을 많이 추출하기 때문에 오래 멈춰있는 것이고중간에 보면 실제 얼굴 주변에 박스가 쳐지는 것을 볼 수 있다.그래서 실제로 캐스케이드 검출을 하게되면 얼굴 주변에 박스가 쳐지게 되고 박스가 3개 이상 검출되어야만실제 얼굴로 인식하게 된다.
그리고 얼굴의 크기가 다양할 수 있기때문에 박스자체를 키워가면서 분류하기도 한다.
OpenCV에서는
cv2.CascadeClassifier 의 클래스 형태로 들어가있고 미리 학습되어있는 정보를 불러와서
내가 찾고자하는 객체를 검출하는 기능을 제공한다.
그래서 cv2.CascadeClassifier.load( filename ) 에서
객체의 특징 , 정보를 담고있는 XML 파일로 불러올 수 있게끔 되어있다.
아래 사진을 보게되면 생성자를 호출함과 동시에 해당 XML 파일을 불러오게끔 할 수도 있고
load 함수를 호출하여 XML 파일을 불러올 수도 있다.

해당 XML 파일은 아래 링크에서 구할 수 있다.
https://github.com/opencv/opencv/tree/master/data/haarcascades
GitHub - opencv/opencv: Open Source Computer Vision Library
Open Source Computer Vision Library. Contribute to opencv/opencv development by creating an account on GitHub.
github.com

이후 위 XML 파일을 실제로 사용하기 위해서는
CascadeClassifier 멀티스케일 객체 검출 함수 를 사용해야한다.
cv2.CascadeClassifier.detectMultiScale ( image, scaleFactor, minNeighbors, flags, minSize, maxSize ) -> result
image : 입력 영상 ( cv2.CV_8U )
scaleFactor : 영상 축소 비율. 기본값을 1,1,
minNeighbors : 얼마나 많은 이웃 사각형이 검출되어야 최종 검출 영역으로 설정할지를 지정. 기본값은 3.
flags : ( 현재 ) 사용되지 않음
minSize : 찾고자하는 객체의 최소 크기. ( w, h ) 튜플
maxSize : 찾고자하는 객체의 최대 크기. ( w, h ) 튜플
result : 검출된 객체의 사각형 정보 ( x,y,w,h )를 담은 numpy.ndarray.
shape=(N,3). dtype=numpy.int32.
detectMultiScale을 이용해서 여러가지 크기의 객체를 찾을수 있게끔 해준다.
위 함수는 입력영상만 줘도 동작은 하지만 나머지 인자들을 적절한 값으로 바꿔주게되면
검출 속도를 향상시킬 수 있게된다.
예를들어서 scaleFactor가 기본값이 1.1 로 되어있는데 입력영상을 1.1로 축소한다는 방식으로
Document에는 나와있지만 실제로는 내부에서 검출하는 사각형의 크기를 1.1배씩 키워가면서 검출하게된다.
그럼 이 부분을 1.2로 키워주게되면 특정 크기의 객체는 검출을 못할가능성이 있지만 속도가 훨씬 빨라지게
되는 것을 느낄 수 있다.
그리고 minNeighbors 는 위 유투브 영상에서 설명했듯이 얼굴위치에 몇번을 검출해야지만 그 위치를
얼굴의 위치로 볼 것인지에 대한 인자이다.
min,maxSize는 알고있다면 입력해주는 것이 속도를 크게 향상시킬 수 있는 방법이다.
실제 코드를 보게되면

CascadeClassifier 함수를 보게되면 ' haarcascade_frontalface_alt2.xml 파일을 불러오게되는데
위 XML 파일 리스트를 참고하게되면 정면얼굴검출의 xml 파일인 것을 알 수 있다.
알려져있는 것으로는 alt2.xml 파일이 그 중 가장 괜찮다는 것으로 알려져있다.
그리고 faces 변수에 detectMultiScale 함수를 사용해서 실제 얼굴이 검출된 바운딩 박스정보를 입력해준다.
( x, y, w, h ) 의 튜플형태의 값이 반환되게 된다.
반환된 값을 rectangle로 만들어서 실제로 검사를 진행해보면

위와같이 lenna 의 얼굴이 검출되는 것을 볼 수 있다.
여기서 scaleFactor 를 1.2로 높여주고, minSize 를 (100,100 ) 으로 주게되면 모든 값을 기본값으로 쓴것보다
2~3배 정도 빨라지는 것도 테스트를 통해 확인할 수 있다.
그리고 눈 검출에 관한 코드도 구현되어 있는데 코드를 보게되면
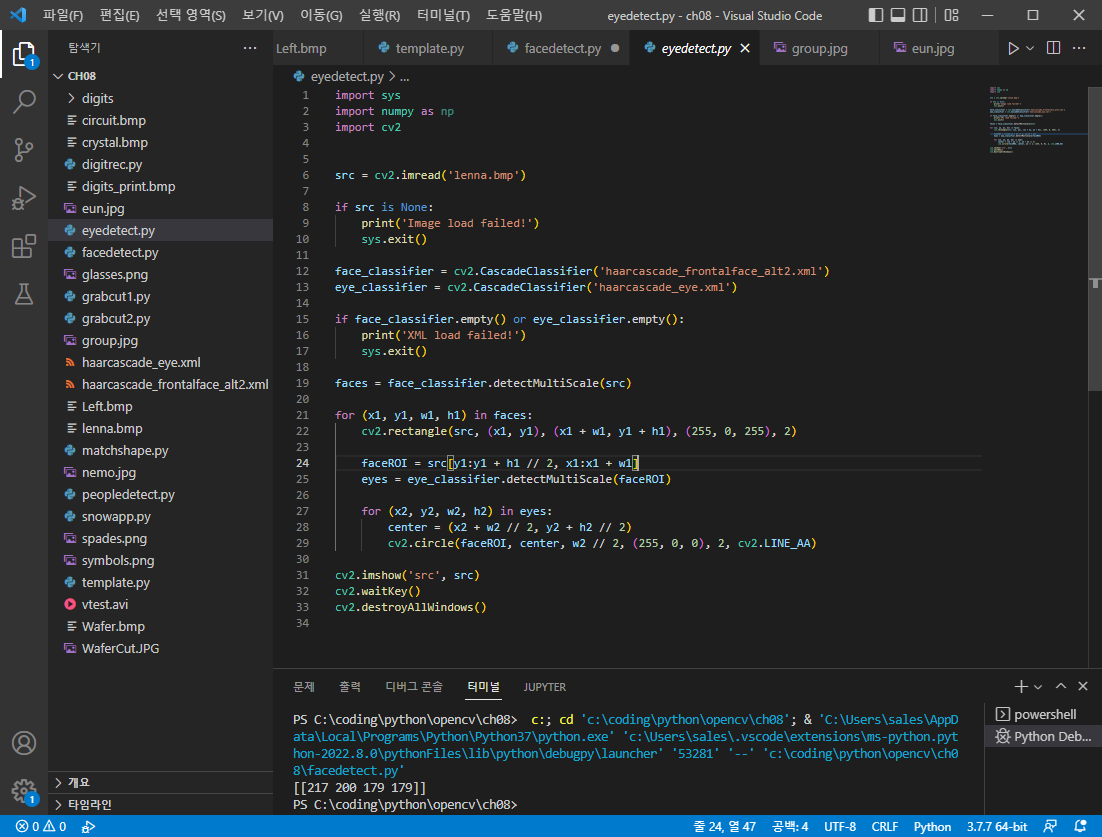
위 코드가 실행되는 방식은 일단
입력 영상에서 얼굴을 먼저 검출한 뒤 해당 바운드 박스를 ROI로 설정하여
ROI 내부에서 다시 눈 검출을 진행하는 방식의 순서로 진행이 된다.

이 외에도 러시아 자동차 번호판 검출, 사람 전신 검출 등의 xml 파일을 사용한
결과 영상을 가져왔다.

위와같이 얼굴이나 사람전신 등등의 haarcascade 방식이 간단하게 몇줄의 코드로 검사할 수 있는 점에서는 좋지만
현재시점 ( 강의시점 2020년 ) 으로 봤을때는 딥러닝에서 사용하는 SingleChartDetector 라고 하는 기법으로 사용하는것이
조금 더 정확하다.
그렇기에 간단하게 분류하고 싶다고 한다면
캐스케이드 분류를 사용하는 것도 나쁜방법은 아니다.
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr
'Program > OPEN_CV' 카테고리의 다른 글
| [Open CV] 영상 분할과 객체 검출 _ 실전코딩 ( 스노우앱 ) (0) | 2022.06.18 |
|---|---|
| [Open CV] 영상 분할과 객체 검출 _ HOG 보행자 검출 (0) | 2022.06.17 |
| [Open CV] 영상 분할과 객체 검출 _ 템플릿매칭 ( 인쇄체 숫자 인식 ) (0) | 2022.06.15 |
| [Open CV] 영상 분할과 객체 검출 _ 템플릿 매칭 (0) | 2022.06.14 |
| [Open CV] 영상 분할과 객체 검출 _ 모멘트 기반 객체 검출 (0) | 2022.06.13 |