웹 구조는 어떻게 구성되어있는가?
일단 웹이 실제로 어떻게 만들어지는가?
우리가 www.naver.com 이라는 url을 창에 입력하게되면
네트워크를 타고 naver.com이라는 url을 가진 컴퓨터에 접속 요청을 하게 된다.
그러면 해당 컴퓨터에서는 접속에 대한 응답을 해주고 다시 역으로 돌아오게되는데 그렇게 되면
컴퓨터 인터넷으로 해당 주소에 접속을 할 수 있는 것.
그럼 우리가 받은 것은 과연 무엇일까?
우리는 크롬, 파이어폭스, 웨일 등에서 렌더링과정을 거치게 된다.
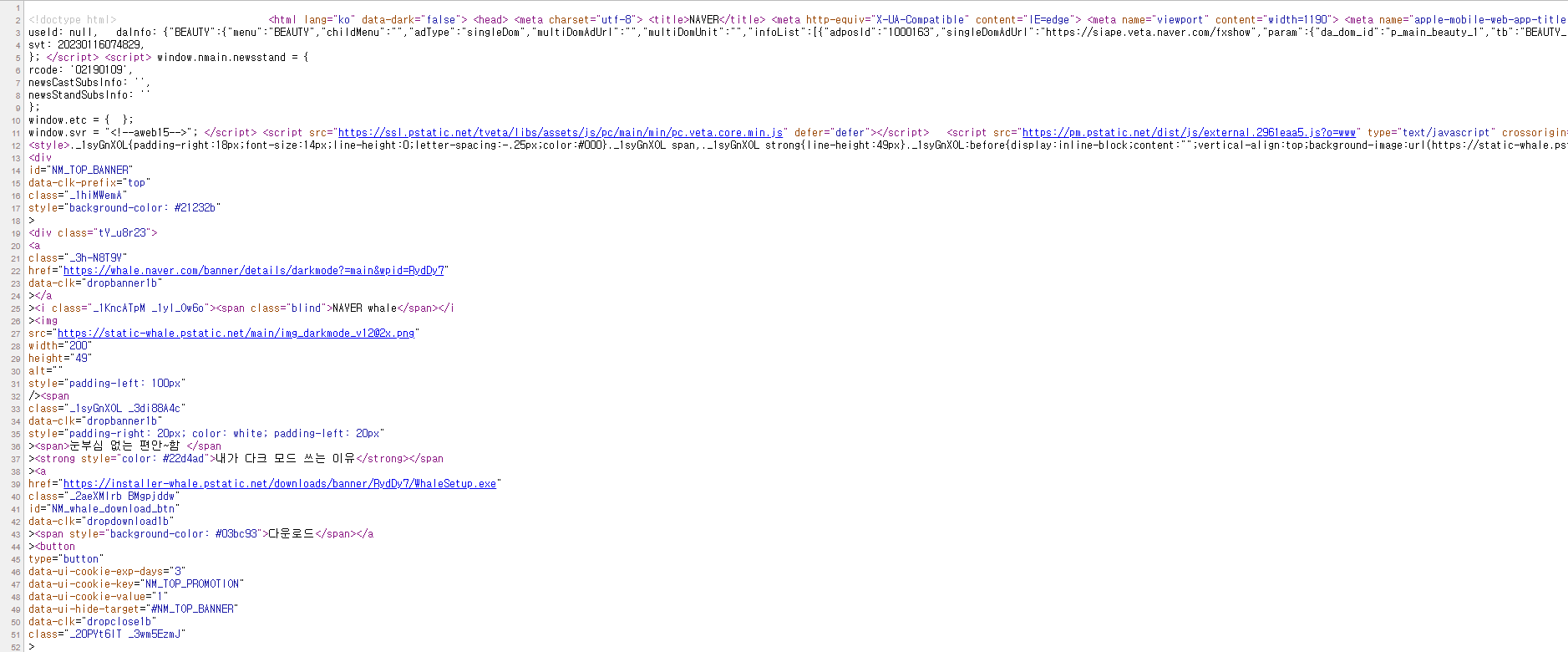
즉, 네이버에서는 위와같이 html이라는 규칙으로 만들어진 코드를 제공해주고
크롬, 파이어폭스, 웨일등의 도구에서 해당 html규칙을 렌더링을 해서 우리에게 보여주는 구조이다.
이게 우리가 보고있는 웹의 기본적인 구조이다.
요즘은 렌더링이나 접속,응답이 굉장히 빠르기 때문에 실시간으로 이미지나 글자들이 바뀌는 것도
너무 간단하게 볼 수 있다.
일단 예를들어 네이버 Finance를 크롤링하는 방법부터 설명해보면
네이버 Finance에 있는 코스피, 코스닥 장마강 지수 데이터를 가져오는 방법에 대해서 알아보자
https://finance.naver.com/sise/sise_index.naver?code=KPI200
코스피 : 네이버 증권
관심종목의 실시간 주가를 가장 빠르게 확인하는 곳
finance.naver.com
네이버 금융 코스피 200의 사이트에 접속하게 되면 위에서 나온 것처럼 해당 소스를 볼 수 있다.
그런데 우리가 보고자 하는 일별 시세 데이터에는 전체소스에 나와있지 않다.
우리가 일반 사이트에 들어가서 우클릭을 하게되면
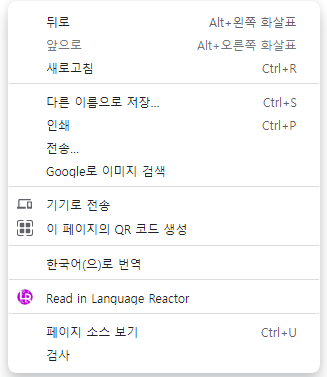
위와같은 창이 나오게 되는데 여기서 페이지 소스보기만 나오는 구조가 있고
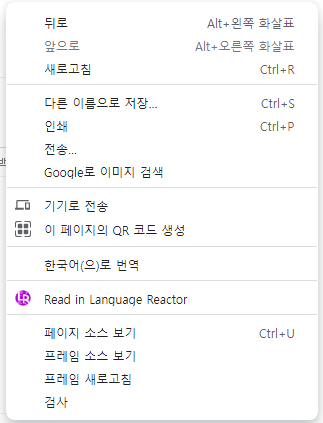
프레임 소스보기가 같이 나오는 구조가 있다.
만약 페이지소스에 우리가 찾고자하는 데이터가 없다면 프레임소스에 있을 가능성이크기 때문에 찾고자 하는 데이터에서
우클릭으로 구조를 살펴보면 좋을 것 같다.
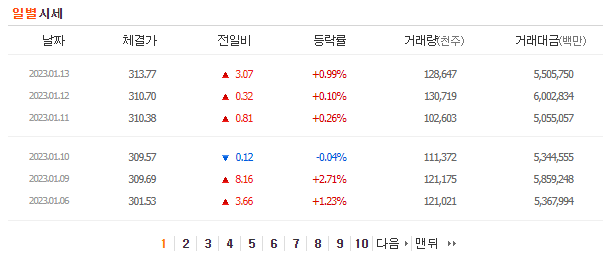
일별 시세에 대한 데이터를 살펴보기 위해서는 프레임 소스를 봐야하는데 프레임 소스에 대한 url을 살펴보면 아래와같다
view-source:https://finance.naver.com/sise/sise_index_day.naver?code=KPI200&page=3
view-source:https://finance.naver.com/sise/sise_index_day.naver?code=KPI200&page=4
view-source:https://finance.naver.com/sise/sise_index_day.naver?code=KPI200&page=5
...
위와같이 필요한 페이지마다 일련의 규칙을 띄는 것을 볼 수 있다.
따라서 우리가 필요한 데이터의 url을 자동으로 보기위해서는
파이썬에 아래와같은 주소값을 넣으면 된다.
page_url = f "view-source:https://finance.naver.com/sise/sise_index_day.naver?code=KPI200&page={page_no}"
'Program > 파이썬' 카테고리의 다른 글
| [Python] Pandas 사용 (0) | 2023.01.17 |
|---|---|
| [Python] Pandas (0) | 2023.01.17 |
| [Python] 함수(Function) (0) | 2023.01.09 |
| [Python] 자료형 함수 (0) | 2023.01.07 |
| [Python] 반복문 ( for ) (0) | 2023.01.07 |