
딥러닝에서 영상을 다룰 때 필수적으로 사용되고 있는 CNN이라는 구조에 대해서 알아본다.
컨볼류션 신경망 ( CNN : Convolutional Neural Network )
- 영상 인식 등을 위해 필수적으로 사용되고 있는 딥러닝에 특화된 네트워크 구조
- 일반적으로 레이어가 많이 들어가있으면 딥러닝이라고 할 수 있기는 하지만
영상쪽에서는 특히 CNN구조가 들어가야지만 딥러닝이라고 하는 인식을 갖고있음
- 일반적 구성 : 컨볼루션 ( convolution ) + 풀링( pooling ) + ... + 완전 연결 레이어 ( FCN )
( 완전 연결 레이어는 없는 경우도 있음 )
Convolution 이라는 용어는 예전 필터링을 배울때 나왔었던 용어이기도 합니다.
https://opencv-master.tistory.com/53
[Open CV] 필터링 _ 필터링 이해하기
영상의 필터링이란? - 영상에서 필요한 정보만 통과시키고 원치 않는 정보는 걸러내는 작업이다. 영상처리에서 필터링은 2가지 방법이 존재한다. - 주파수 공간에서의 필터링 ( Frequency domain fi
opencv-master.tistory.com
Convolution 이라고 하는 것은 필터링이라는 개념이 딥러닝에 추가된 개념이라고 볼 수 있다.

위 이미지에 나와있는 것 처럼 3 x 3의 필터를 만들고 필터결과를 만들어서 중간단계의 값을 만들어내고
그리고 중간단계의 값을 모두 사용하는 것이 아니라 다시 부분영상 ( 2 x 2 ) 으로 추출하여
다시 풀링이라는 1 x 1 의 영상으로 추출하는 것을 컨볼루션 + 풀링 레이어라고 부르고
그리고 추출된 풀링 레이어를 1열로 쭉 세워서 일반적인 신경망 MLP ( Multi Layer Perceptron )을 추가적으로 더 할 수 있다.
그래서 최종적으로는 내가 분류하고싶은 클래스 개수만큼 Output을 만들어내고 여기서
가장 큰 값을 영상의 클래스로 설정하는 형태로 동작한다.
컨볼루션 레이어 ( Convolution Layer )
컨볼루션 레이어는 필터링을 하기 위한 것이고 필터링이라고 하는 것은 어떤 특징을 찾아내기 위한 것이다.
해서 딥러닝에서도 필터를 만드는데 필터링에서 사용되는 값은 마스크 값은 내가 지정하는 것이 아니라
딥러닝 학습이 되면서 그 안에 들어가는 필터 마스크값이 자동으로 결정되는 것이다.
필터마스크라고 하는데 들어가있는 값 자체가 딥러닝 학습에 의해 나온 Weight 값으로 자동 계산이 되는 것이다.
- 2차원 영상에서 유효한 특징 ( feature ) 를 찾아내는 역할
- 유용한 필터 마스크가 학습에 의해 결정됨
- 보통 ReLU 활성화 함수를 함께 사용함

위 이미지에서 32x32x3 에서 3은 컬러이미지를 뜻하는 것이고 이 영상에 5x5의 필터링을 적용시킬 때
결과를 내는 방식은 동일하다.
같은 위치에 있는 것을 모두 곱하고 더해서 하나의 값이 만들어지게 된다. ( 필터의 기능과 같음 )
그런데 해당 필터를 6개를 만들어준다.
그렇게되면 해당 필터들을 거친 결과 28 x 28 x 6의 영상이 6가지 나오게된다.
( 여기서 28 x 28 이 나오게 된것은 5 x 5 필터를 써서 가장자리가 잘린 영상 )
풀링 레이어 ( Pooling Layer )
- 유용한 정보는 유지하면서 입력 크기를 줄임으로써 과적합 ( overfitting ) 을 예방하고 계산량을 감소시키는 효과
- 최대 풀링 ( max pooling ) 또는 평균 풀링 ( average pooling ) 사용
- 학습이 필요 없음

위 이미지처럼 4 x 4 영상을 2 x 2로 줄이는 것인데 평균을 내어서 줄일 수도 있지만
max값을 사용하는 방법이 많은 알고리즘에서 선호하는 방법이다.
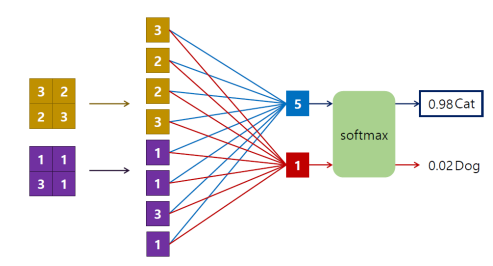
완전 연결 레이어 ( Fully Connected Layer )
처음에 있는 이미지를 Convolution 하고 필터링하고 Resize 하고 다시 필터링하고 Resize하는 방식으로
진행이 되는데 결과적으로는 해당 영상을 1열로 세워야 한다.
- 3차원 구조의 activation map ( H x W x C ) 의 모든 값을 일렬로 이어 붙임
- 인식의 경우, 소프트맥스 ( softmax ) 레이어를 추가하여 각 클래스에 대한 확률 값을 결과로 얻음
학습된 컨볼루션 레이어 필터의 예

필터링은 기본적으로 Correlation이라고 보면 되는데 이는 필터와 비슷한 성분이 있으면 값이 크게 나온다.
위 이미지를 보면
Low Level Featur 은 초반부에 나오는 필터이고
1번은 세로방향의 엣지를 검출하기 위한 필터이다.
2번은 컬러형태의 필터로 녹색이 많은 부분을 검출하기 위한 필터이다.
3번도 마찬가지로 빨간색이 많은 부분을 검출하기 위한 필터이다.
그리고 Mid-Level 이나 High Level 로 가게되면
4번 처럼 바퀴형태의 필터링을 진행할 수도 있고
5번 처럼 새의 머리를 찾아내는 필터링을진행할 수도 있다.
컨볼루션 신경망의 예
필기체 숫자 인식을 위한 LeNet-5 ( Lecun et al.,1998)
- CNN 원조
- 28 x 28 필기체 숫자 영상을 32 x 32 로 확장하여 만든 입력 데이터를 사용
- 전체 7개 레이어 : Conv-Pool-Conv-Pool-FC-FC-FC

Alex Net ( krizhevsky et al.,2012 )
- 2012년 ILSVRC ( ImageNet Large Sclae Visual Recognition Challenge ) 영상 인식 분야 1위
1000개의 카테고리, 120만개의 훈련 영상, 15만개의 테스트 영상
- Top-5 Error : 15.4% ( 다른 컴퓨터 비전 기반 방법들 > 25% )
- 하드웨어의 제약으로 2개의 GPU 사용

VGG16 ( Simonyan and Zisserman, 2014 )
- 2014년 ILSVRC ( ImageNet Large Scale Visul Recognition Competition ) 영상 인식 분야 2위
- Top-5 Error : 7.3%
- 컨볼루션 레이어에서 3x3 필터만 사용
- 총 16개의 레이어로 구성
- 이후 Top-5 Error 를 6.8%까지 줄여서 다시 논문을 발표했음

GoogLeNet ( szegedy et al.,2014 )
- 2014년 ILSVRC ( ImageNet Large Scale Visul Recognition Competition ) 영상 인식 분야 1위
- Top-5 Error : 6.7% ( 사람 : 5.1 % )
- 총 22개의 레이어로 구성
- Inception 모듈

이는 앞에서봤던 VGG16보다 구조가 엄청나게 복잡하기 때문에
사람들이 실제로 사용할 때는 VGG16을 조금 더 선호해서 사용했다는 말이 있다.
그래서 각각의 알고리즘을 공부를 해야 딥러닝에대해 제대로 이해할 수 있는데
현재는 위 알고리즘들이 있다는 것만 설명하기 위해서 언급한 것이다.
'Program > 딥러닝' 카테고리의 다른 글
| [Open CV] 딥러닝 _ GoogLeNet 영상 인식 (0) | 2022.07.22 |
|---|---|
| [Open CV] 딥러닝 _ MNIST 학습 모델 사용하기 (0) | 2022.07.21 |
| [Open CV] 딥러닝 _ OpenCV DNN 모듈 (0) | 2022.07.19 |
| [Open CV] 딥러닝 _ 딥러닝 학습과 모델 파일 저장 (0) | 2022.07.18 |
| [Open CV] 딥러닝 _ 딥러닝이해하기 (0) | 2022.07.16 |