2022.06.30 금일은 평균이동 알고리즘에 관한 강의였다.
금일은 평균 이동 알고리즘을 통해 객체를 추적하는 방법에대해서 알아본다.
Detection vs. Recognition vs. Tracking
- Detection ( 검출 ) : 영상에서 찾고자 하는 대상의 위치와 크기를 알아내는 작업
Recognition ( 인식 ) : 주어진 영상이 무엇인지 판별하는 작업 ( classification , identification )
Tracking ( 추적 ) : 동영상에서 특정 대상의 위치 변화를 알아내는 작업
이 전 프레임의 객체가 현재 프레임의 어디에 위치해있는지
( Mean Shift , CamShift , Optical Flow , Trackers in OpenCV 3.x )
Ex) 스마트폰 카메라에 기본적으로 내장되어있는 기능 중 사람의 얼굴을 찾아내는 것을 Detection ( 검출 ) 이라고하고
얼굴 인식이라고 하는 것은 해당 얼굴이 누구인지를 찾아내는 것
평균 이동 ( Mean Shift ) 알고리즘이란?
- A non-parametric feature-space analysis technique for lcating the maxima of a density function
데이터가 가장 밀집이 되어있는 부분을 찾아내는 방법
- 국지적 평균을 탐색하면서 이동
- 모드 검출 ( mode seeking ) 알고리즘
평균이동 알고리즘
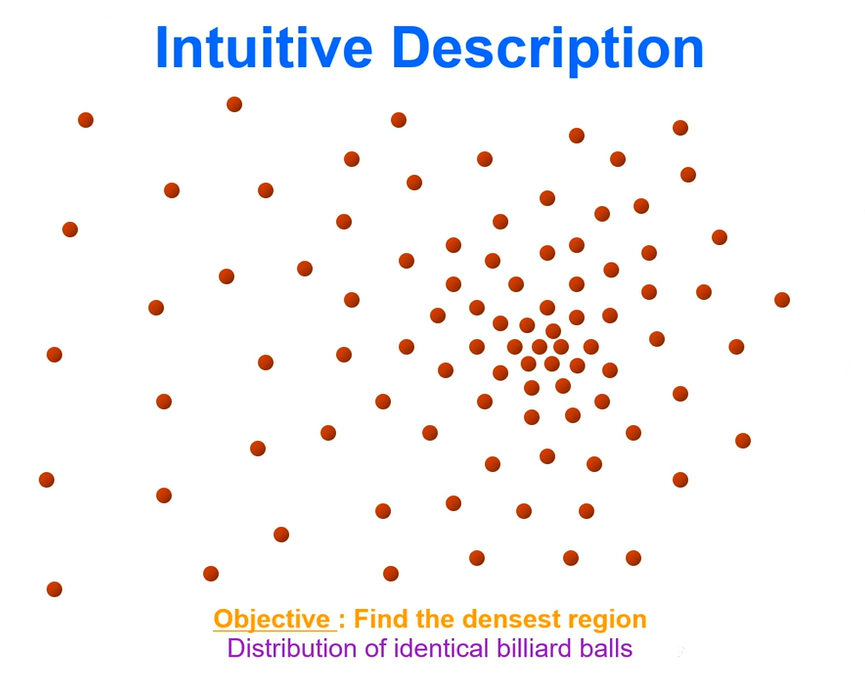
위 사진에서 빨간 점들이 데이터 분포라고 보고 위 데이터 중 가장 많은 데이터가 분포하는 위치를 찾고싶으면
임의의 크기의 원을 그려서 원 내부에 들어있는 데이터들의 x좌표를 구해서 평균을 내고 y좌표를 구해서 평균을 낸다.
그렇게되면 원 내부에서 데이터의 평균위치가 나오는데 해당 평균위치가 나오게되면 그 평균위치를 중심으로해서
원을 다시 그리게된다.
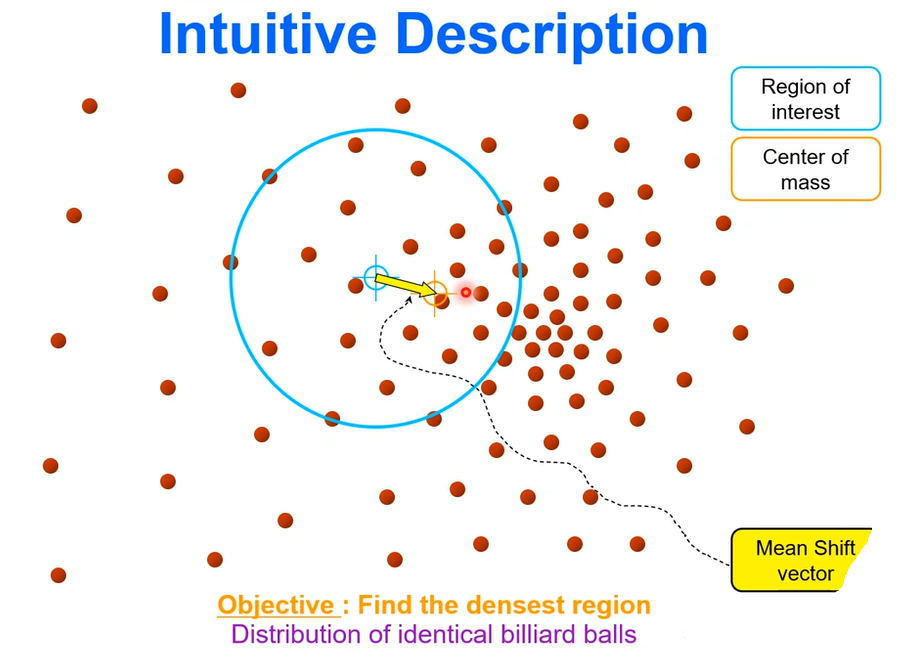
위와같은 작업을 계속해서 반복하다보면 결국 가우시안 분포의 중심으로 원이 이동하게된다.그렇게 이동 중 거의 이동이 없다고 판단되면 해당 부분을 데이터 분포가 밀집된 곳으로 판단한다.
평균 이동 알고리즘을 이용한 트래킹
cv2.meanShift ( probImage , window , criteria ) -> retval , window
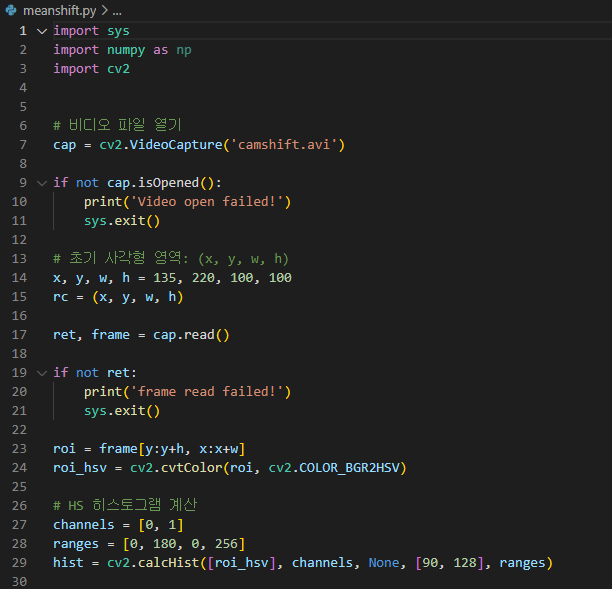
probImage : 관심 객체에 대한 히스토그램 역투영 영상 ( 확률 영상 )
widnwo : 초기 검색 영역 윈도우 & 결과 영역 반환
criteria : 알고리즘 종료 기준 ( type, maxCount , epsilon ) 튜플
(e.g.) term_crit = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1)
-> 최대 10번 반복하며, 정확도가 1이하이면 (즉, 이동 크기가 1픽셀보다 작으면 ) 종료.
retval : 알고리즘 내부 반복 횟수
프로그램 동작 방식
1) 추적할 객체 등록 - 첫 번째 프레임에서 추적할 객체의 위치를 지정 - HSV 색 공간에서 HS 히스토그램을 구함
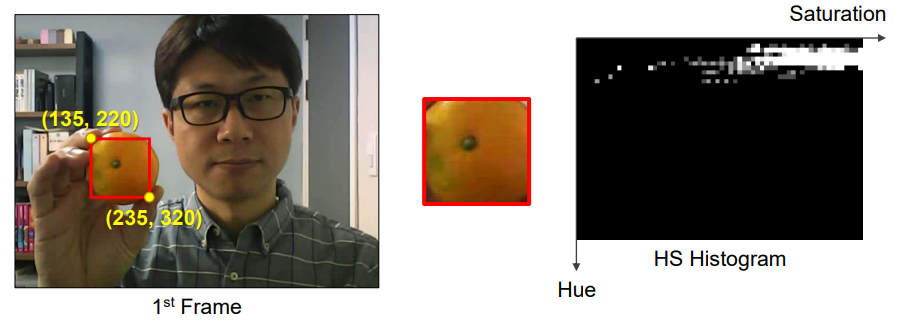
2) 평균 이동 추적
- 매 프레임마다 히스토그램 역투영을 수행
- 여기에 평균 이동 알고리즘을 적용하여 객체를 추적
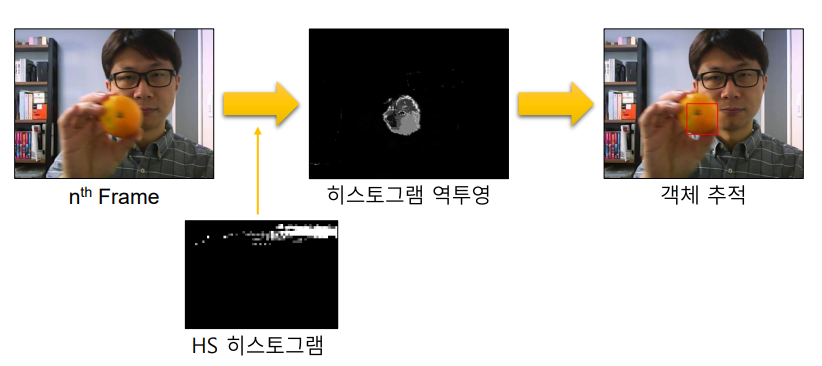

RGB를 HSV로 변환해서 사용하는데 HS만 사용하고 V에 대한 값은 보지 않는다.V는 조명에 의한 값이기 때문에 컬러를 추적하기 위해서는 V를 빼고 추적해야 더 효율이 있다.
그리고 검출하는 사각형의 크기가 지정해준 사각형의 크기에서 벗어나지 못하기때문에추척하는 객체의 크기가 달라져도 사각형의 크기가 변하지 않는 단점이 존재한다.
그래서 해당 단점을 보완할 수 있는 알고리즘은 다음시간에 다시 배워본다.
* 히스토그램 역투영
* cv2.calcBackProject( [hsv], channels, hist, ranges, scale, dst=None ) -> dst
images: 입력 영상 리스트
channels: 역투영 계산에 사용할 채널 번호 리스트
hist: 입력 히스토그램 (numpy.ndarray)
ranges: 히스토그램 각 차원의 최솟값과 최댓값으로 구성된 리스트
scale: 출력 역투영 행렬에 추가적으로 곱할 값
dst: 출력 역투영 영상. 입력 영상과 동일 크기, cv2.CV_8U.
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr
'Program > OPEN_CV' 카테고리의 다른 글
| [Open CV] 객체추척과 모션벡터 _ 카나데옵티컬플로우 (0) | 2022.07.02 |
|---|---|
| [Open CV] 객체추척과 모션벡터 _ 캠시프트 알고리즘 (0) | 2022.06.30 |
| [Open CV] 객체추척과 모션벡터 _ 배경차분 _ MOG 배경모델 (0) | 2022.06.28 |
| [Open CV] 객체추척과 모션벡터 _ 배경차분 _ 이동평균배경 (0) | 2022.06.27 |
| [Open CV] 객체추척과 모션벡터 _ 배경차분 _ 정적배경차분 (0) | 2022.06.26 |